博文
【All about norm】一文理解深度学习中的norm:batch norm、layer norm及其意义
||
1、Normalization概述
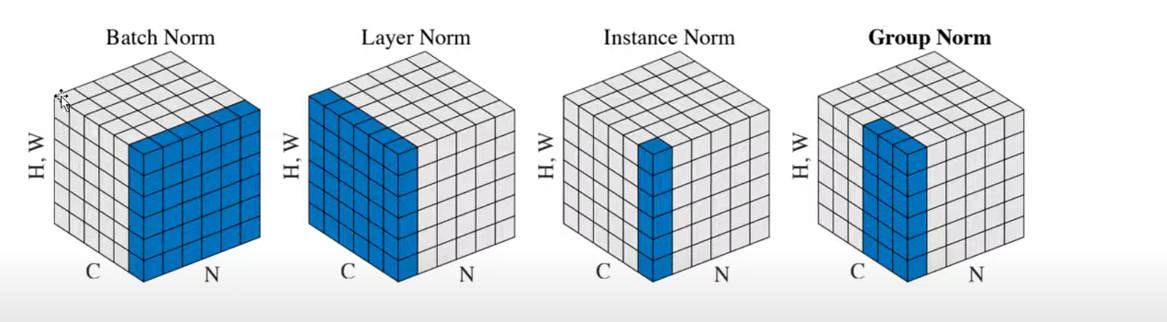
2、通俗理解Batch Normalization的计算(HOW)
如图所示,假设1个mini-batch内有N个图像,每个样本通道数为 C,高为 H,宽为 W。
对其求均值和方差时,将在 N、H、W上操作,而保留通道 C 的维度。
具体来说:就是把所有样本的第1个通道纳入计算得出均值及方差;
所有样本的加上第2个通道纳入计算得出均值及方差;
所有样本的加上第3个通道纳入计算得出均值及方差;
其具体计算公式:

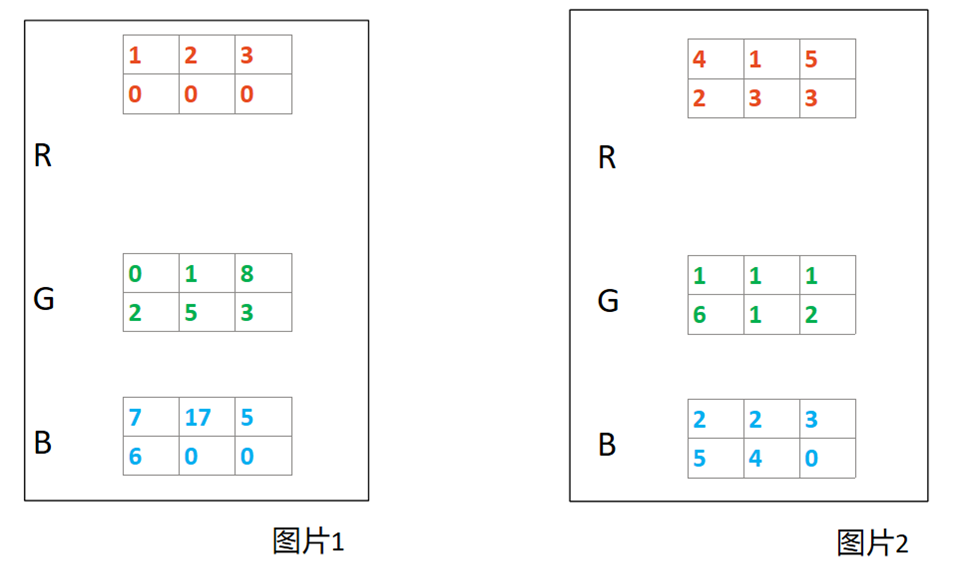
具体而言:以RGB图像处理为例,假设我们目前的batch_size = 2, 图像尺寸为2x3,示意图如下
其对应的pytorch代码为

那么这里,很显然, N=2、H=2,W=3, 而通道 C =3. 注意,这里不妨将图像的H和W维度的矩阵排列为1维向量,则可以认为HW(合并写法)=6

![]()
![]()
![]()
![]()
![]()
![]()
那么对图片1和图片2进行BN,结果如下图所示:

3、通俗理解Layer Normalization的计算
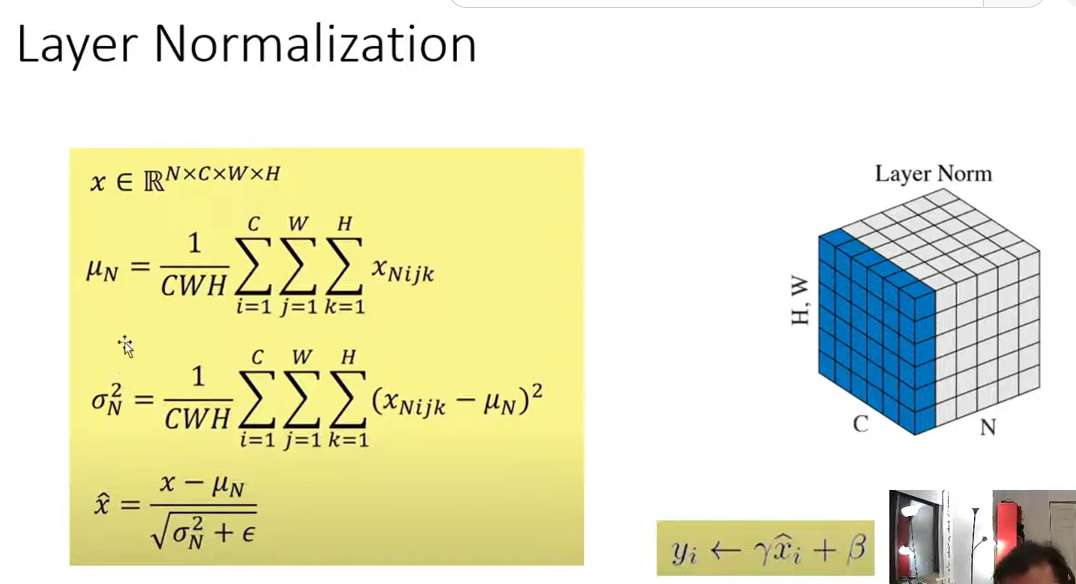
若是layer norm,则是对图片1中RGB三个通道中的18个点做统计,得出一个u1和sigma1,这里分别为3.33,4.31;对图片2中RGB三个通道中的18个点做统计,得出一个u2和sigma2,这里分别为2.56,1.69, 不再详述。

4、如何理解batch norm 以及layer norm?
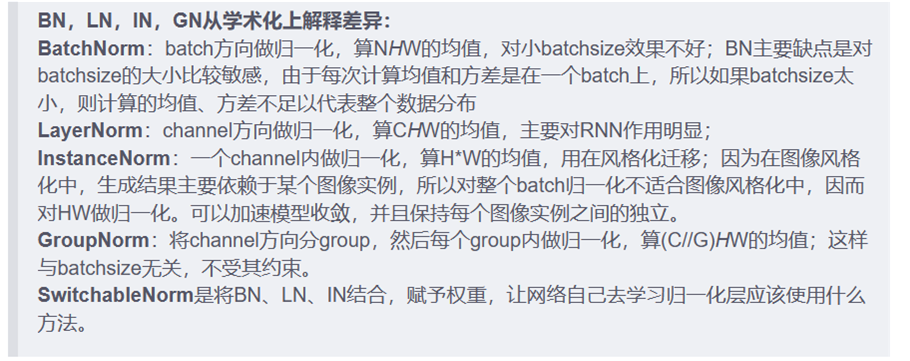
*batch Norm一般用于图像处理(CV)之中,layer norm一般用于(NLP)之中;
*对图像而言,BN是对一个batch中的同通道的所有特征(所有点)看成是一个分布,并将其标准化。例如RGB中的R通道,这说明每个样本的某个确定通道的特征可以比较。
*对文本而言,LN是把一个样本(e.g.,句子)的所有词义向量视为一个分布,有几个句子就有几个分布,对其进行标准化。
*BN的好处:最主要的作用是加速神经网络训练,并使模型训练更加稳定(可以适应大的lr,对参数初始化不敏感),避免了人工适应调整网络超参数。
5、关于训练/预测时的BN差别
我们知道BN在每一层计算的 μ与 sigma2 都是基于当前batch中的训练数据,但是这就带来了一个问题:我们在预测阶段,有可能只需要预测一个样本或很少的样本,没有像训练样本中那么多的数据,此时 μ与 sigma2的计算一定是有偏估计,这个时候我们该如何进行计算呢?
利用BN训练好模型后,我们保留了每组mini-batch训练数据在网络中每一层的 μ_batch与 sigma_batch^2 。此时我们使用整个样本的统计量来对Test数据进行归一化,具体来说使用均值与方差的无偏估计:
![]()

其中m代表的是mini-batch的个数。
由此,对测试数据可以做如下计算:

在实际计算的过程中,无须保留训练过程中的所有历史值再求平均。因为训练早期模型为收敛时的值没有太大的价值,甚至会干扰对均值和方差的估计。
因此可加入一个momentum参数。 该参数作用于mean和variance的计算上,这里保留了历史batch里的mean和variance值,借鉴优化算法里的momentum算法将历史batch里的mean和variance的作用延续到当前batch。一般momentum的值为0.9 , 0.99等. 多个batch后, 即多个0.9连乘后,最早的batch的影响会变弱。
而最后的“scale and shift”操作则是为了让因训练所需而“刻意”加入的BN能够保证整个network的囊括能力。( 这个操作既可以和原始输入一样,也可以比例化和平移)
下面我们用pytorch实现以下完整的BN:

6、BN优势小结
BN对各种极端的超参数都有很强的适应能力。在训练的过程中使用BN我们完全可以使用较大的学习率加快收敛速度,而且不会影响模型最终的效果。BN通过将每一层网络的输入进行normalization,保证输入分布的均值与方差固定在一定范围内,并在一定程度上缓解了梯度消失,加速了模型收敛;并且BN使得网络对参数、激活函数更加具有鲁棒性,降低了神经网络模型训练和调参的复杂度;最后BN训练过程中由于使用mini-batch的mean/variance作为总体样本统计量估计,引入了随机噪声,在一定程度上对模型起到了正则化的效果。
(转载请注明洪峰-科学网博客)
参考资料:https://zhuanlan.zhihu.com/p/87117010
https://blog.sciencenet.cn/blog-3396477-1407467.html
上一篇:语音深度学习分类解析(一)
下一篇:深度学习环境安装教程[Win10+Anaconda5.2.0+Tensorflow+RTX2080Ti+Cuda10