博文
[转载]一文读懂倾向值匹配(PSM)
||
说明:本博客与微信公众号“林墨”同步更新,所有内容均为原创,可授权转载请扫码关注“林墨”公众号。
一个只能揭示是什么、而不能解释为什么的学科的影响是有限的。因果推论是让科学计量学、图书情报学研究更有解释力、更有影响力的最有效方法。林墨计划面向青年学者和学生推出一系列因果推论方法在科学计量学中应用的科普文章,欢迎关注并传播。
赵镇岳/ 南京大学

注:图片来源于百度
匹配、倾向值匹配的基本思路
下图展示了一个简化了的但典型的对某种政策、药物等的treatment effect进行研究的概念框架。以我之前的一项研究为例,我的目的是探究科学家从海外跳槽到中国大陆之后业绩有没有变好,在这里,接受treatment指的就是跳槽到中国大陆,outcome指的就是业绩变化。
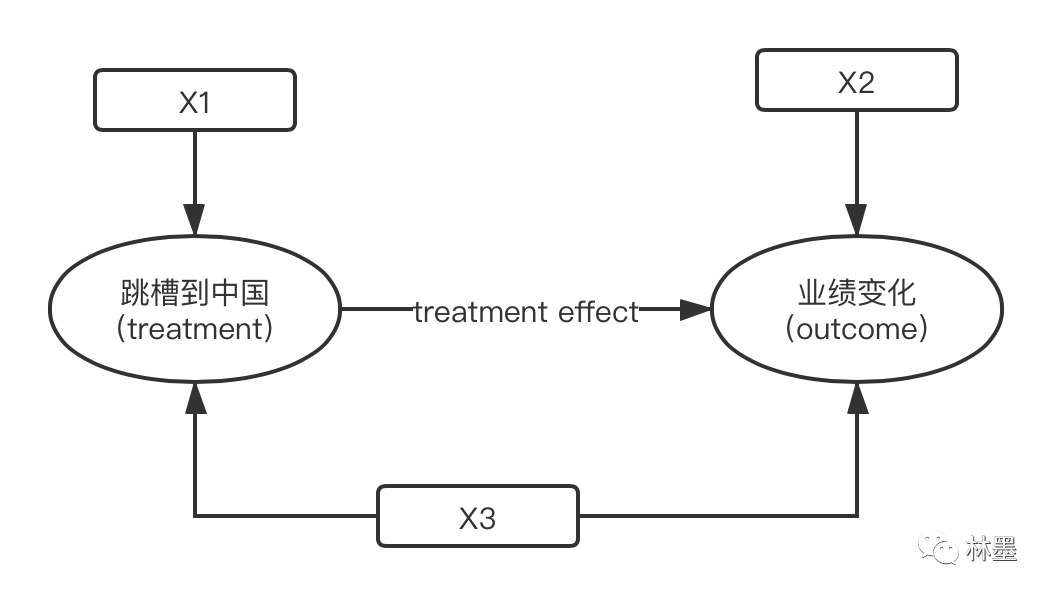
注:图片来源于本文作者
整个过程涉及到的协变量可以被分为三类:
(1)X1:仅对是否接受treatment有影响的变量,比如这位科学家是不是很喜欢大陆
(2)X2:仅对outcome有影响的变量,比如这位科学家来大陆之后生活是否适应
(3)X3:对是否接受treatment和outcome都有影响的变量,比如他是不是处在上升期(中国大陆的人才引进政策主要针对的是正处在上升期的科学家)
在这个框架之下,如果我们研究的对象是treatment effect,那么X1我们可以完全不考虑;不控制X2的话,treatment effect系数的显著性可能会受到影响,但估计值的无偏性不受影响。
不控制X3导致的问题就是选择性偏误(selection bias),如果我们发现来大陆的科学家都有了业绩提升,这未必是因为他们来了大陆(即接受了treatment),也可能因为这些人正好都处在职业生涯的上升期,去哪儿都能有业绩提升。
这时候如果要通过matching找一个控制组,比如找一些同样跳槽但是去了其他国家的人,那么X3就是我要用来进行匹配的变量。通过匹配使实验组和控制组在X3上“距离”足够近,选择性偏误就消失了。
Matching方法的基本工作原理
不同matching方法的区别就在于对距离的计算方法不同,比如exact matching规定两个个体的所有变量取值都一样距离就是0,否则就是正无穷;coarsened exact matching把exact matching的条件放宽到一个区间;此外也有人用其他的距离,如欧式距离,马氏距离等,如果两个个体的标准化距离的差小于一个阈值,就认为两个样本match(当然,对于有的方法比如熵平衡匹配(entropy balancing matching),这个距离可能比较抽象,但思想都是通过控制X3来优化某个目标函数)。
倾向值匹配就是一种用个体接受treatment的倾向性(propensity)的差值作为距离来对样本进行匹配的方法,倾向值 的定义如下:
即给定协变量的情况下,个体接受treatment的概率,这个值的计算一般基于logit回归或probit回归,有时候也用线性版本的,比如 ,当然软件包都实现好了,我们不用操心。
当然,有时候几种方法也可以混着用,比如对性别进行exact matching,在此条件上进行倾向值匹配;或者在倾向值的阈值之内再进行马氏距离匹配。
倾向值匹配的使用方法
(1)选择匹配用的协变量--X3
如上图所示,从理论上来说,所有对是否接受treatment和outcome同时有影响的变量都应该被用于匹配。
如何确定哪些变量符合条件呢?要基于以往的文献和自己对现实情况的科学理解。当然现实问题是复杂的,当我们不能够完全确定某个变量是不是对两者都有影响时,最好还是把它加进来,因为遗漏变量的代价一般大于引入无关变量的代价。
有些人会在选好协变量之后跑一个logit或者probit回归,以treatment为被解释变量,选好的协变量为解释变量,来确认选的变量的确都对是否接受treatment有影响。虽然这不能证明这些变量一定对outcome也有影响,但基于之前的讨论,“疑似”的最好还是也加进来。
(2)计算倾向值并进行匹配
R语言的MATCHIT包已经完整地实现了各种常用的倾向值匹配方法,比如:
1 m.out <- matchit(treat ~ covariate1 + covariate2 + ..., data = name_of_the_dataframe, method = "nearest") 2 m.data <- match.data(m.out)
第二句返回的m.data就是匹配好的数据了,注意,虽然匹配的过程是给每一个实验组个体寻找对应的(一个或多个)距离最近的控制组个体,但匹配好的数据是不含这个对应关系的。
(3)检查协变量X3的平衡性
实验组和控制组在倾向值上的平衡只是消灭选择性偏误的必要条件,而不是充分条件。倾向值的相等并不意味着所有变量都相等,两个在所有协变量上差异都很大的个体也能够有相同的倾向值。
因此,我们还需要一个条件,即用于匹配的各个协变量在两组之间已无明显差异,也就是协变量都平衡了。这大概也是所有matching方法的必要条件吧!如图1所示,我们认为每个属于X3的协变量都对outcome有影响,如果其中某个在两组之间仍然不平衡,审稿人完全可以认为outcome的差异是由它引起的。这一步可以用一句代码实现:
1 summary(m.out)
也可以使用t-test检查具体变量在两组间的差异是否显著:
1 with(m.data, t.test(target_covariate ~ treat))
如果仍有哪个变量不平衡,可以把matchit函数的卡钳值参数调小再试试。我有个老师说,加一些交互项高阶项有时候也能让协变量平衡,但这是玄学,也说不出规律。如果最后实在还有少量协变量不平衡,那就在下一步中处理吧。
(4)分析计算treatment effect
如果协变量找全了,使用倾向值匹配选出了控制组,且协变量全都平衡了,那我们就可以认为selection bias已经不存在了,两个组的outcome可以直接被用来比较了,这时候可以将两个组outcome的平均值之差作为treatment effect,再做一个t检验看看差异是否显著就解决问题了。
如果还有协变量没有平衡,那还得将它控制了才能对两组的outcome进行比较。可以跑个回归,以没平衡的协变量为控制变量,以treatment为解释变量,以outcome为被解释变量。不过既然都跑回归了,为了得到漂亮的R方,并让treatment有更小的标准误,还是把X2和X3里的变量全都加进来作为控制变量吧,懂的都懂。

[1] Rubin, D. B. (2001). Using propensity scores to help design observational studies: application to the tobacco litigation. Health Services and Outcomes Research Methodology, 2(3-4), 169-188.
[2] Stuart, E. A. (2010). Matching methods for causal inference: A review and a look forward. Statistical science: a review journal of the Institute of Mathematical Statistics, 25(1), 1.
[3] Angrist, J. D., & Pischke, J. S. (2008). Mostly harmless econometrics: An empiricist's companion. Princeton university press.

https://blog.sciencenet.cn/blog-1792012-1223129.html
上一篇:科研项目申请的评审改为摇号?真有国家这么干
下一篇:来中国后,他们发表了更多的论文