ВЉЮФ
Python_ЛњЦїбЇЯА_змНс15ЃКФЃаЭадФмЦРМлжИБъ
|
confusion matrix:ЛьЯ§Оиеѓ
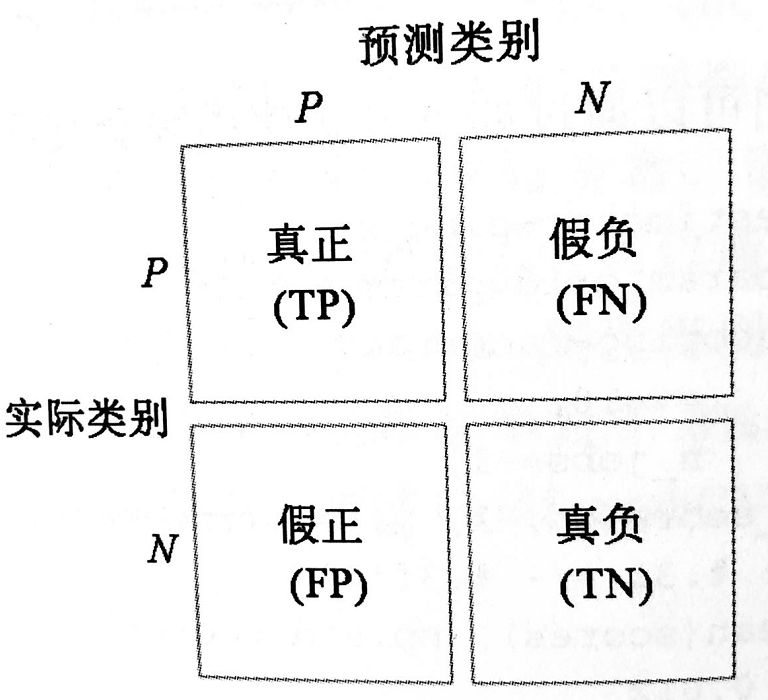
дЄВтЮѓВюERRЃК
дЄВтзМШЗТЪACCЃК
![]()
ЕБРрБ№Ъ§СПВЛОљКтЪБЃК
еце§ТЪTPRЃК

Мйе§ТЪFPRЃК
![]()
зМШЗТЪPRE, precision:

ейЛиТЪREC, recallЃК

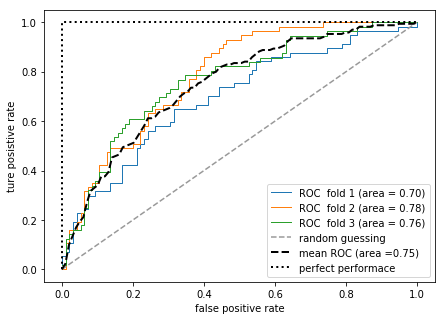
ROCЃЈReceiver Operator characteristiЃЉЧњЯп
РћгУМйе§ТЪЁЂеце§ТЪЕШжИБъбЁдёЗжРрФЃаЭЃЛ
РэЯыЗжРрЦїЃЌМйе§ТЪЮЊ0ЁЂеце§ТЪЮЊ1ЃЛ
ЛљгкROCЧњЯпЃЌПЩвдМЦЫуArea under the curveЃЈAUCЃЉЃЌМДЯпЯТЧјгђЃЛ
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.learning_curve import learning_curve
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.learning_curve import validation_curve
from sklearn.grid_search import GridSearchCV
from sklearn.svm import SVC
from sklearn.cross_validation import StratifiedKFold
###############################################################################
df = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data', header=None)
#НЋЪ§ОнЗжГЩбЕСЗМЏКЭВтЪдМЏ
from sklearn.preprocessing import LabelEncoder
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le = LabelEncoder()
y = le.fit_transform(y)
#print(le.transform(['M', 'B']))
#НЋЪ§ОнЗжГЩбЕСЗМЏКЭВтЪдМЏ
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=1)
###############################################################################
pipe_lr = Pipeline([
('scl', StandardScaler()),
('clf', LogisticRegression(penalty='l2', random_state=0))])
from sklearn.metrics import roc_curve, auc
from scipy import interp
X_train2 = X_train[:,[4,14]]
cv = StratifiedKFold(y_train, n_folds=3, random_state=1)
fig = plt.figure(figsize=(7,5))
mean_tpr = 0.0
mean_fpr = np.linspace(0, 1, 100)
all_tpr = []
for i, (train, test) in enumerate(cv):
probas = pipe_lr.fit(X_train2[train], y_train[train]).predict_proba(X_train2[test])
fpr, tpr, thresholds = roc_curve(y_train[test], probas[:,1], pos_label=1)
mean_tpr += interp(mean_fpr, fpr, tpr)
mean_tpr[0] = 0.0
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, lw=1, label='ROC fold %d (area = %0.2f)' % (i+1, roc_auc))
plt.plot([0,1], [0,1], linestyle='--', color=(0.6, 0.6, 0.6), label='random guessing')
mean_tpr /= len(cv)
mean_tpr[-1] = 1.0
mean_auc = auc(mean_fpr, mean_tpr)
plt.plot(mean_fpr, mean_tpr, 'k--', label='mean ROC (area =%0.2f)' % mean_auc, lw=2)
plt.plot([0,0,1], [0,1,1], lw=2, linestyle=':', color='black', label='perfect performace')
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('false positive rate')
plt.ylabel('ture posistive rate')
plt.legend(loc='lower right')
plt.show()#ВЮПМЁЖPython ЛњЦїбЇЯАЁЗЃЌзїепЃКSebastian RaschakaЃЌ ЛњаЕЙЄвЕГіАцЩчЃЛ
https://blog.sciencenet.cn/blog-3377553-1137721.html
ЩЯвЛЦЊЃКPython_ЛњЦїбЇЯА_змНс14ЃКGrid search
ЯТвЛЦЊЃКCategories_of_algorithmsЃЈnon_exhaustiveЃЉЃЌзмНсКмШЋУц