博文
《语义群笔记:端端的端到端与结构》
||
白:“盼望长大的童年”
本来是歧义,常识把它变成了伪歧义。“长大的”和“童年”不搭。
李:“盼望长大的童年”,可以问:1. 谁盼望长大?– 童年;2. 盼望【谁】长大? — 童年;3. 盼望 可能有两个 【human】 的坑。类似的例子有:“盼望到来的幸福” vs “盼望幸福的到来”,当然 还有一个 盼望- 长大(了)的童年。
虽然说似乎不合常识,概念来点弹性的话,也不是说不通:童年的定义里面虽然有没长大的意味,在类比和修辞的意义上,两个概念可以做各种关联和联想。事实上,“不搭”才是诗意的简单有效的手段,保证了想象的空间。
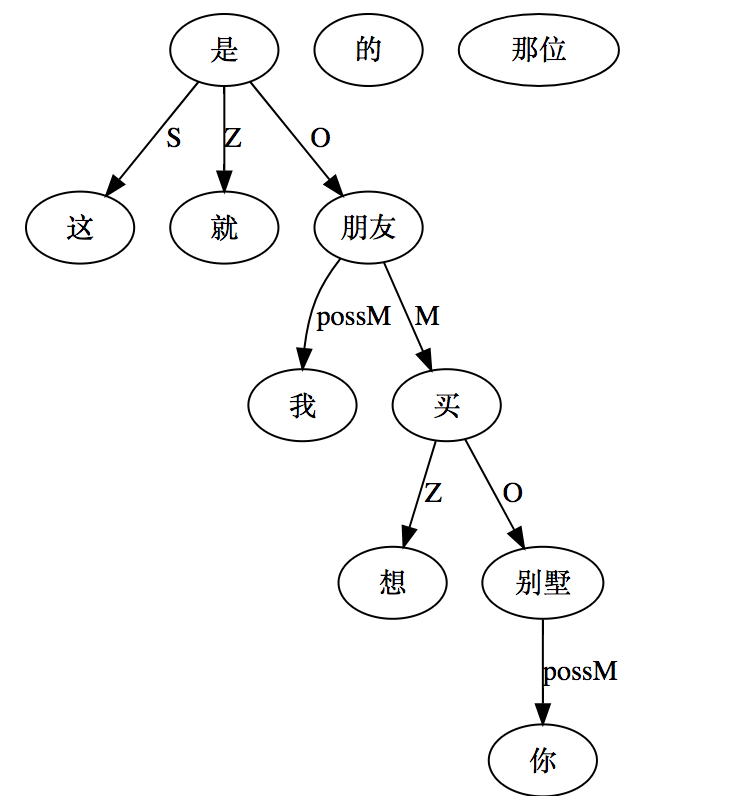
“这就是我那位想买你别墅的朋友”
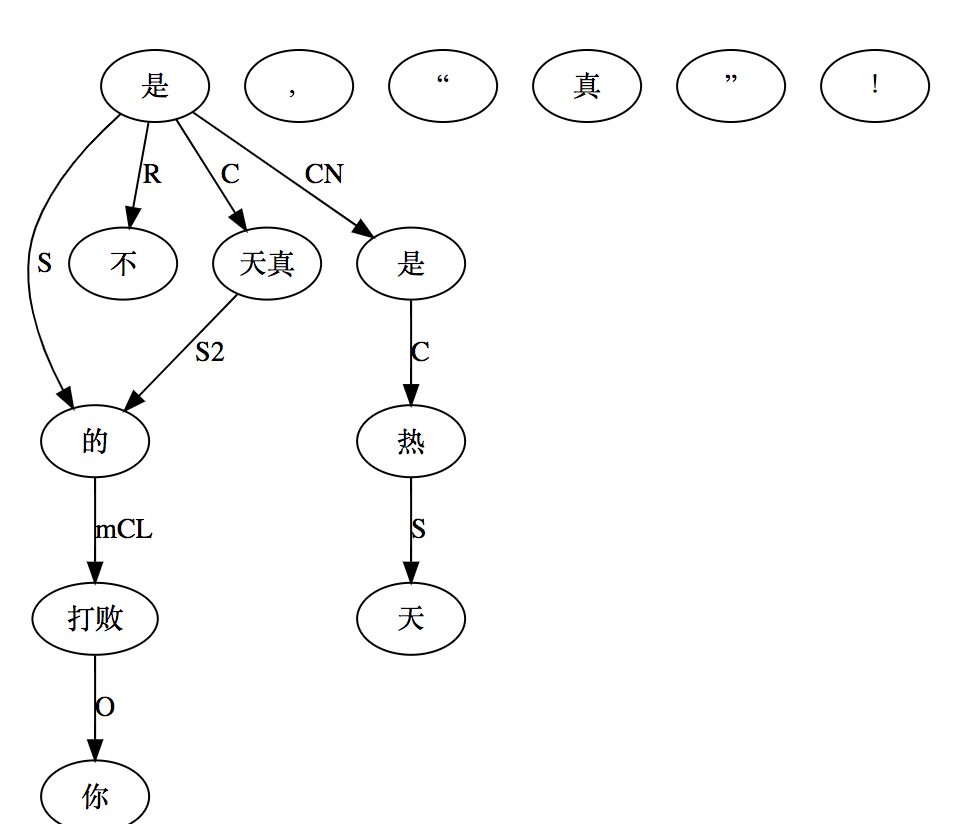
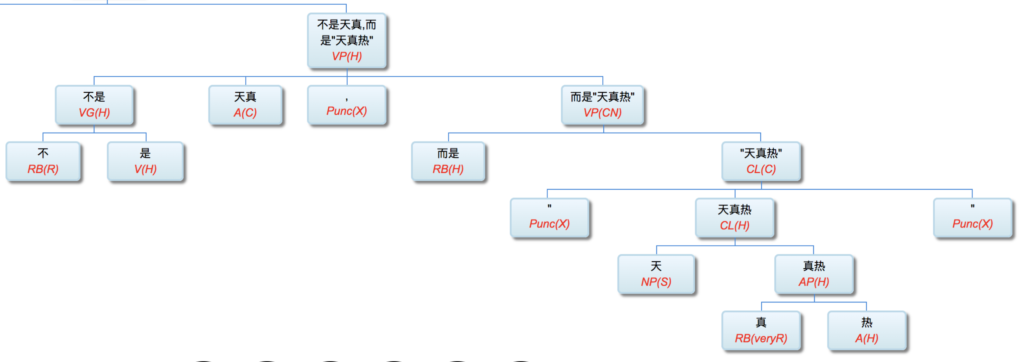
白:【打败你的不是天真,是“天真热”!】
李:不是天真,而是天(真)热:
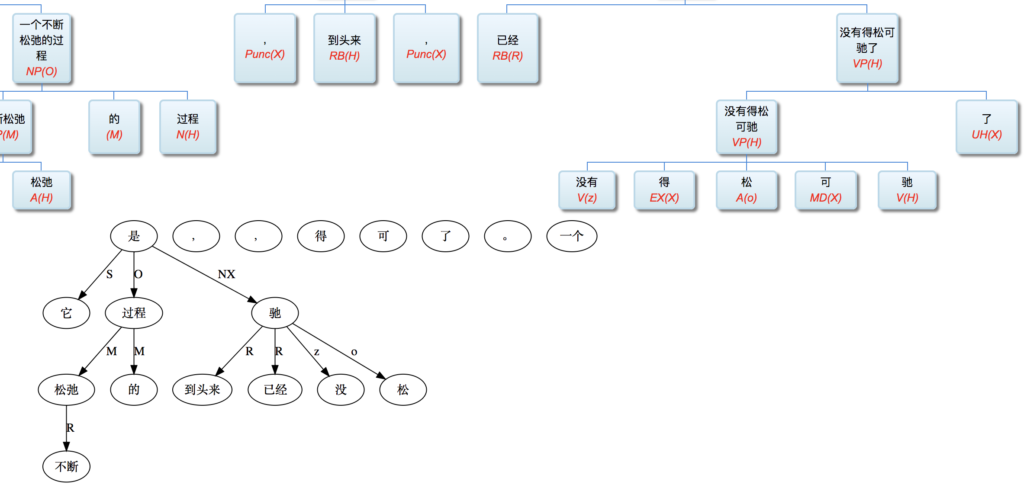
白:“它是一个不断松弛的过程,到头来,已经没得松可驰了。”
李:没得松可驰了 还是 没得弛可松了?没得澡可洗 从来不说 *没得洗不澡。当然 “松弛” 虽然 比照 “洗澡” 的动宾离合词 但自己并不是动宾 而是并列,因此 换位了也不觉得。没得学可习 还是 没得习可学?
成语活用 只要愿意花时间 不是问题 问题仍然是 有多少用场。
Lai:@wei 有什么深度学习有效的方法可以发现这些Dependency?
李:不知道 据说只要有标注 就不是问题。
郭:斯坦福的陈丹琪(danqi chen)和她的导师Manning有个深度学习的dependency parser。应该算state of the art。开源,是stanford coreNLP的一个模块。
谷歌基于这个工作,做了个大数据版,据说准确率“超过人类”。也是开源的。
李:标注可以让目前的系统先自动做,让人去修正(只修正黑白错误,不修正模糊地带或不清晰的地方),这会大量节省人工,所以数据也不是大问题。最大的问题是,这些 dependency 出来了,懂得如何派上用场的 不多。在大半个世界都迷信端到端的时候,缺乏资源去用的话,parsing 就是面壁十年的玩偶。
白:端到端不是问题,问题是端不能容纳结构。
李:神经MT 就是一个端到端典型示范。一端是串 另一端还是串 为什么要容纳结构。只要有可以监督的数据 信息抽取也是如此。
白:关系抽取不是这样的。
李:以前一直以为抽取乃是我结构的长项。最近朋友问我 如果是抽取关系,现存数据库就有亿万,表示 locationOf,whereFrom,bornIn,bossOf 等等关系。这些关系的两端 都在数据库里面,用他们去找语言数据 可以产生难以想象的不用人工的标注大数据。结构的路子一定可以匹敌这种大数据?我觉得很难。这与mt可以一比。
还有一些端到端 结构无从下手 可是端到端可以派上用场,譬如 图片转文字看图说话,和文字转图。这些事儿 有了结构也难以缩短距离。玩结构 玩理解 应该在小数据 多变的domains 以及数据虽大 但无法监督的情况下。这时候 人家“端端的” 根本就不跟你玩,视而不见。另一个就是 打下手 做小三。在人家玩剩下的某些短板上 玩补充作用。譬如 mt,张冠李戴这类问题 可以帮上忙。
神经mt最不可思议的突破是顺畅度。这是当年认为mt无解的一个方面。突破带来的副作用是损失忠实,这点损失 符号结构派其实可以擦屁股的。结构派有个貌似真理的预设,自然语言千变万化 唯有结构化才可以变得 tractable。这话实际上并不尽然。结构化的确可以导致 以较少的patterns 捕捉较多的现象,可是 对于“端端的”系统 对于海量容量和算力 这种 generalizations 的意义大打折扣。推向极端 如果有个现象 两个 patterns 可涵盖一千个变体,如果我真有充分的数据 可以看见这一千个变体足够的重复,全部记住了 或者用另一种非符号化非规则化表达了 embedding (嵌入)抽象了,那么那两条 patterns 还有什么优势呢?何况 符号规则化的本性就是不够鲁棒 免不了漏掉点什么例外。
还有个有意思的现象。以前老以为 起码起码 结构化总是帮助提供了更好的基础 总是归纳了很多现象 没有功劳有苦劳。这个苦劳认不认不重要,客观情形是,满世界没几个人有兴趣利用,一多半也因为没几个人懂得怎么利用和消化,包括业界学习方面的牛人,曾经私下交流过,回答说,引入结构说起来应该有好处,但不好融啊。
绝大多数的端端学习系统有自己的一套比较成熟的 有广大community主流不断集体探索和积累的基于一包词或ngram的各种模型 算法和工具,语言结构横插进来,有异物感,heterogenous evidence,增加了模型复杂度,很容易得不偿失。
牛的 parser 能够开拓市场和被大家接受估计需要相当一段时间,其契机可能是: 1. 端端系统遇到瓶颈或死胡同,不得不探索其他路子的时候;2. 主流中的少数坚持探索利用结构或者结合AI理性主义和经验主义路线的融合派,在算法研究中取得了突破性进展,带动整个领域”产业升级“到结构化。
在此之前,基本上是自产自销,内部消化,用于目前主流“视而不见”无所作为的短板应用场景。(其实很不少,甚至 text NLP 中端端最成熟的 MT,进入领域由于缺乏数据也有很大短板。)
吕:@wei 大赞。
【相关】
https://blog.sciencenet.cn/blog-362400-1172735.html
上一篇:《岁月如歌: 美错》
下一篇:《音乐心情故事:童趣岁月的回放》