博文
给自己五年前的书补一个介绍——动宾搭配的语义分析和计算
 精选
精选
||

李斌,《动宾搭配的语义分析和计算》,世界图书出版公司,2011。
居然还在卖,网购地址:https://item.jd.com/10931705.html?dist=jd
动宾搭配是个老生常谈的题目,这本书能有什么新花样呢?
要想出新,得有新数据、新方法,传统的拍脑袋研究要有,新的认知理论要有,真实的搭配数据要有,建模计算要有……好吧,此书将认知语言学理论、语料库语言学、语言计算理论和机器学习技术融合起来,围绕动宾之间的语义选择限制问题展开研究。基于大规模数据,对不同动词对宾语选择限制的多样性和强度差异,做了系统标注和统计分析。从主观性和认知事件框架的角度,揭示了动宾搭配多样性的深层次约束,描写了词语褒贬的指向问题,利用选择限制对动宾搭配的转喻本体做了自动理解实验并验证了隐喻理论的有效性,对明喻句的自动识别实验取得良好效果。
这么说还是挺抽象,那就说说动宾搭配的核心问题吧。全书想阐明动词对宾语的选择限制到底是语义类的,还是语义属性(特征)的,或者其他的什么要素。在研究之前,综述了国内外有关搭配和动宾搭配的研究历史,总结出基于语义类的语义选择限制是学界重点研究视角,但语义选择限制本身没有经过大规模数据的验证。书中第二章介绍了,基于知网的辅助分析软件平台的设计实现,使用知网的语义类、语义特征(义原)对动宾搭配数据,采用相对熵、公共集合算法进行了自动的分析。分析发现,像“眨-眼”、“养育-人”这样选择限制较强的动词仅占全部动词的一半,宾语的开放性比较普遍。该软件也可用于其他类型搭配的语义选择限制自动获取。
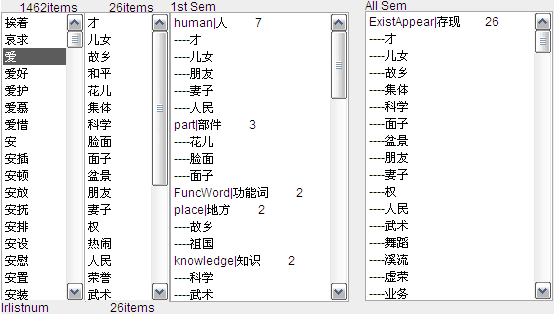
(图:基于知网的辅助分析软件平台观察搭配语义选择限制,爱的宾语列表及语义类、语义特征自动聚类结果)
作者也够拼的,为了各位都能看到实例,特地开发了网络版哦,方便查找动宾搭配的主观性和认知框架。
http://cognitivebase.com/force/examples/force/vo/vo_nju_col.php

在动宾搭配中,宾语通常呈现出开放性,这在论文的第三章有基于语义词典知网(HowNet)的详细调查。通过分析1460个动词及其4万多条搭配,总结了出了动态性、主观性和认知事件框架三个要素。比如,传统上认为“问题”是一个语义类,可是除了典型的一些词语“难题”、“困难”之外,“住房”、“入托”、“温饱”等词都是一种动态认定的或者默认的难题。借用认知语言学的观点,一个事物是否是“问题”,完全在于语言使用者在语境中的动态认定(profile)。这样就回答了为何静态的语义知识库难以满足动宾搭配识别的问题。
第四章,则尝试扩展Fillmore的框架语义学理论,以汉语动宾搭配实例的分析,构建新的语言模型。比如,动词“当心”的宾语有两类,一类是保护的对象,如,钱包,脑袋;一类是威胁物,如,石头、骗子。这在现有的语文词典中没有得到区分,在语言理论上也都作为“受事patient”。而使用Fillmore的框架语义学理论则区分得很漂亮,但Fillmore的理论尚未关心框架元素之间的认知关系问题。本章总结了两大类常见的认知关系,“宿主-属性”关系和“容器-内容”关系。这些关系,可能就是人的一些基本的认知方式。另外,还探讨了“排火车票”这样的特异搭配,认为是“排队”和“买火车票”的叠加。这些分析,目前还没有建立好计算模型,但感觉解释力比较不错,有拓展空间,当然完全解决的难度也比较大。
第五章提出了“褒贬指向”的术语,把传统的褒义词、贬义词的说法进行细化。比如,“夸奖”是施事褒扬受事,“包庇”则是说话人贬低施事和受事。通过分析900多个褒贬词语,确定每个褒贬词语究竟褒贬哪些语义角色,对动宾搭配而言也更具有指导意义。因为传统研究中,很多论文认为“包庇”的宾语一定是贬义词,现在看确实是不准确的表述,应该是说话人贬斥的对象。这也是动词静态要求和说话人主观性认定的体现。书中进一步给出了褒贬指向和配价的关系(见下表)。同时,还进行了词语褒贬度的自动判定和褒贬指向的半自动判定。
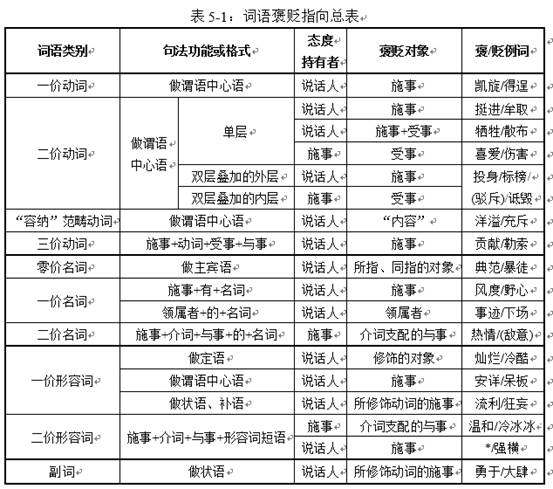
第六章做了一个有意思的计算实验,利用动宾之间的选择限制、相关词、词语相似度方法,寻找常见转喻(也就是借代)的本体,在中英文动宾搭配上的实验都得到了不错的结果。比如“赞扬红领巾拾”,根据“赞扬”的宾语往往是“人”,再和“红领巾”的相关词做语义相似度计算,就可以自动得出转喻的本体“少先队员”(下表为计算结果)。但目前只能做到显著度比较高的借代的理解。


本书第三、四章使用认知事件框架对动宾搭配进行了分析,但还缺少计算上的实验。第七章选择了“像”这个搭配范围比较广,又可以作为比喻词的动词作为研究个案。首先,手工标注了1500多个含非名词“像”的句子,在带有比喻用法的句子上标明了“像”的比喻框架“本体、喻体和相似点”。而后使用机器学习方法对“像”的比喻和非比喻用法进行分类,开放测试F值达到了89%;自动识别比喻的本体、喻体和相似点,F值分别达到了73%、86%和83%。该成果可直接应用于明喻的识别和计算。
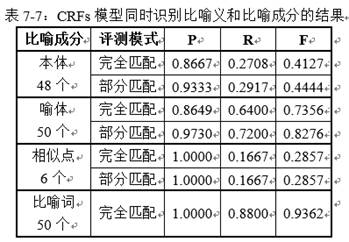
总体上看,本书想追求理论分析、语言模型和计算评测的相容性。研究工作看起来显得有些松散。作者本来想不断地拔高上升为一个系统的理论,把主观性和认知事件框架完全推到前台,再对两者展开系统地计算工作,把认知和计算充分结合起来。可是,做着做着发现难度太大了,感觉再做三两年也不够。
于是,作者又花了五年时间,构建了汉语的大规模认知属性库,进一步解决搭配中的语义限制问题。详情请关注后续介绍。

一点彩蛋
有没有觉得本书封面太土,是的,因为是丛书,没办法。其实作者设计的原图是这样的。
作者简介:
李斌,1981年生,南京师范大学文学院语言科技系副教授。1999~2003年就读于南京师范大学文学院汉语言文学(文科基地)专业,获学士学位。2006年、2009年,继续在文学院攻读研究生,分获计算语言学方向硕士和博士学位。后留校任教,讲授《中文信息处理概论》、《数据结构》、《数理逻辑》、《人工智能》、《数据库编程》等研究生和本科课程。2010~2013年南京大学计算机科学与技术系在职博士后,2015年美国Brandeis大学计算机系访学一年。研究领域包括词法分析、认知语义计算、语料库技术、语法理论等方面。在国内外期刊和会议上发表论文40多篇,主持完成国家社会科学基金青年项目一项,参与完成国家自然科学基金、国家社会科学基金、211工程项目等多个研究项目。
适用人群:本书是一本难得的将认知语言学理论、语料库、语言计算理论和机器学习技术融合研究的专著,对语言学、现代汉语、句法语义学、计算语言学等方向的科研人员、研究生、高年级本科生具有较高参考价值。
https://blog.sciencenet.cn/blog-39714-1069575.html
上一篇:人工智能的第三次浪潮还能火多久?
下一篇:中文AMR语料库的构建工作简介