博文
也谈数据与眼睛——读“莫让数据迷住双眼”有感
||
2011年4月30日,读湘明君“莫让数据迷住双眼”,颇有感受,也谈一点感想,互为切磋。
1、对已有的知识和结论,比如说可以或已经建立相应的数学模型,那么对于给出的条件,应有相应的结论。这时,由模型和求解条件可以解算出结论,这在数学上是“正问题”,这些数据可以构成一个数据集,记为A。
不妨认为与此相近的模型,以及该模型在类似条件下的结论数据“都在A中”,即A所在的那一类,称“A”为已知结论数据集。
2、现在,设计一个研究方案,进行实验研究,得出一系列实验数据,自然要问,这些实验数据是“已知结论数据”呢,还是不是呢?即在A中与A是同类,还是不在A中与A不同类。
能不能让这组实验数据自己说话?
3、为此,设计一个具有学习功能的分类器,如下图所示。
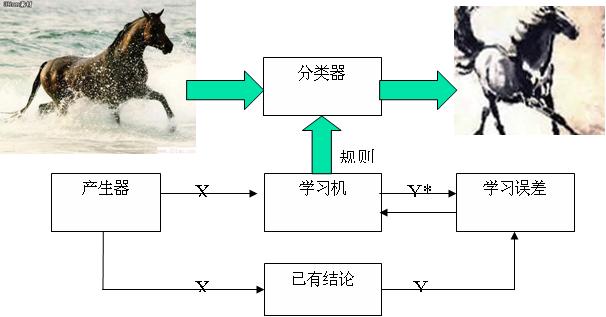
这样,通过分类器来让数据自己说话。
4、如果实验数据通过分类器的判定后,是不属于A类的有效数据,即认为是新结论,可由此建立新的模型。这时,相对于“正问题”而言,是“反问题”。如果已知模型结构而要确定模型中的参数,则是模式识别问题,如果没有模型的结构,则要构建新的理论。
不妨记新模型及与此类似的模型所得的结论数据集为B,称为新结论数据集。那么B与A在空间分布上应有较大的距离。
再用B去修正分类器,应该能得到更有效的分类器。这是一种逼近的思想。
5、如果人站在一个合适的位置上,应该用眼看出较好的分界线,如下图所示。

显然,较粗的实垂线作为两类的分界线较好,因为有较宽的隔离带,如虚线所示,实斜线作为两类的分界线不好,因为离两类太近。
在数学上这种用眼看出的方法,可用支撑向量机。
6、下面的图,是一张用支撑向量机作的分类的实验图。

现在对SVM的研究已经很多了,应该有许多应用。
7、从视觉方面来看,数据应是视网膜上的光点,人对光点的反映起初可以是模糊的,经过滤波后而观察到数据结构的结构密度、连通性和结构方向,从而可辨识数据的类结构。分类是有导师的学习,也是模式识别的基础。类之所以能加以区分,这依赖于数据的局部特征,人能看清这些局部特征,显然是在并行处理中将数据看成了图像而进行特征提取。用这些特征也许能算出数据的局部结构和各向异性从而对数据进行分类。
8、这些是从数据处理的角度来谈的,但没有认真思考,而我对湘明先生所研究的专业方向就更不懂了,但在诗词上我们是可以很好地沟通与交流的。
五一劳动节就这样劳动了。
https://blog.sciencenet.cn/blog-40049-439166.html
上一篇:不要轻言孤独——为小丛写
下一篇:醉蓬莱•次韵卫军英《醉蓬莱》贺柏舟伉俪