博文
新冠状病毒感染后症状模拟分析过程与结果简述
 精选
精选
|||
I. 模拟数据的生成:
为了更清晰地展现分析结果,病毒感染后临床症状采用常用的case-control模式,分别模拟重度和轻度患者。考虑到有个别临床表型数据(如年龄)跟感染后症状高度相关,我们设置了2个强相关特征,此外,还设置了20个不同程度的线性相关特征,3个非线性相关特征,和20个噪音不相关特征。一共设立了45个特征数据。感染患者样本分成三类,分别用不同的随机种子数生成:包括500个训练(training)样本,300个验证(validation)样本,和300个独立验证(independent test)样本。
考虑到实际可能会存在部分数据缺失,在模拟数据中引进了少量缺失数据(表示为NA),并在分析的时候通过imputation的方法补缺。
II. 人工智能分析过程和结果:
我们分别采用了两种方法进行分析。
(一) 选择四种常用机器学习方法:rf(随机森林),SVM(支持向量机),K个最近邻居(KNN),glmnet,并采用greedy ensemble方法对其进行整合,对训练样本进行特征提取,优化参数,通过验证样本选择最优特征和模型,并通过独立样本检验得到最终预测结果。
a) 对特征进行相关性排序,结果见图1,可以看到


(a) (b)
图1 (a) 基于glmnet算法的特征重要性排序,两种强相关特征和线性相关特征排在前面; (b) glmnet和rf两种不同算法得到的重要性排序高度相关,揭示结果的稳定性
b) 将特征按重要性排序,分组,用4种不同算法建模,最后采用greedy ensemble方法整合4种模型。对验证组样本的预测结果见图2。由图2可以得出结论,经过4种算法集成后的ensemble算法在25个特征的组合得到了最优模型。这个结论基本符合我们模拟生成的特征:2个强相关,20个线性相关,3个非线性相关。

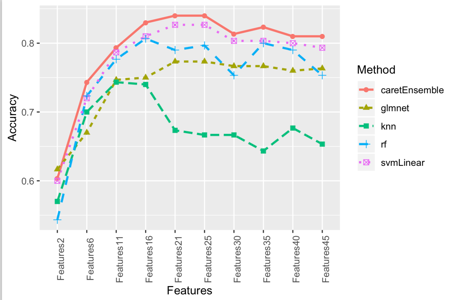
(a) (b)
图2 验证组样本不同特征组合的预测表现:(a) auROC; (b) Accuracy
c) 将训练组跟验证组的ensemble模型预测数据合并,可以观察到训练组的under-fitting和over-fitting的现象在25个特征得到最佳解决(图3)。16个特征之前是under-fitting,25个feature之后是over-fitting。


(a) (b)
图3 训练组跟验证组的ensemble模型预测结果:(a) auROC; (b) Accuracy
d) 采用25特征的ensemble模型对300个独立样本进行验证,预测结果和auROC曲线见图4。预测结果的AUC为0.957,总体预测准确率为:0.883。


(a) (b)
图4 300独立样本验证结果:(a)预测结果密度分布图:X轴是实际症状,Y轴是预测结果(大于等于0.5预测为case,小于0.5为control); (b) auROC曲线
(二) 深度学习(Deep learning)方法
a) 分析使用Keras深度学习框架,两层隐藏层结构的模型设计,100次最大分析周期(epoch)
b) 合并训练集和验证集样本,重新随机划分70%(560个)位训练集,30%(240个)为验证集,独立验证样本保持不变。训练集和验证集的准确度(accuracy)和损失(loss)数据见图5。准确率在60个epoch附近达到峰值,为最佳模型。

图5 深度学习训练组跟验证组的分析结果:上图是loss; 下图是 accuracy
c) 300个独立样本验证,准确率为0.89,AUC为0.93(图6)。


(a) (b)
图6 深度学习300独立样本验证结果:(a)预测结果分布:X轴是实际症状,Y轴是预测结果(大于等于0.5预测为case,小于0.5为control); (b) auROC曲线
III. 小结:
根据实际媒体报道和跟一线医生交流,我们推测了新冠状病毒感染后症状跟临床数据的相关程度,并模拟生成1100个样本和45个特征数据,使用两种分析方法:1)4种传统机器学习算法ensemble;2)深度学习,分别来观察人工智能模型对病毒感染后症状的预测能力。进一步测试表明,如果训练样本增加到2000个,300个验证样本和300个测试样本不变,则独立验证AUC可以达到0.97,准确率为0.92。两种方法的独立样本预测结果基本相仿,各种指标都呈现出很好的预测性能,进一步证明了通过人工智能方法进行新冠状病毒感染后症状预测的可行性。
聚焦武汉新型冠状病毒肺炎疫情
https://blog.sciencenet.cn/blog-604918-1216510.html
上一篇:紧急建议开发人工智能模型预测新冠状病毒感染后症状
下一篇:为什么说特斯拉可以依靠现在的技术路径实现L5级别的全自动驾驶