博文
Fastq 格式说明 & (Phred33 or Phred64)
|||
Fastq格式是一种基于文本的存储生物序列和对应碱基(或氨基酸)质量的文件格式。最初由桑格研究所(Wellcome Trust Sanger Institute)开发出来,现已成为存储高通量测序数据的事实标准。以Illumina Casava 1.8+ 的fastq格式为例,fastq格式的形式如下:

每条序列由4行字符表示,上述样例显示有两条序列:
第一行:必须以“@”开头,后面跟着唯一的序列ID标识符,然后跟着可选的序列描述内容,标识符与描述内容用空格分开。
第二行:序列字符(核酸为[AGCTN]+,蛋白为氨基酸字符)。
第三行:必须以“+”开头,后面跟着可选的ID标识符和可选的描述内容,如果“+”后面有内容,该内容必须与第一行“@”后的内容相同。
第四行:碱基质量字符,每个字符对应第二行相应位置碱基或氨基酸的质量,该字符可以按一定规则转换为碱基质量得分,碱基质量得分可以反映该碱基的错误率。这行的字符数与第二行中的字符数必须相同。字符与错误率的具体关系见下文介绍。
在满足上述要求的前提下,不同的测序仪厂商或数据存储商对第一行和第四行的定义有些差别。
第一行,即标识行在Illumina和NCBI SRA中的样式如下:
@HWI-ST1276:97:D1DCYACXX:7:1101:1406:2170 1:N:0:CGACGT
NCBI SRA:
@SRR387514.1 ILLUMINA-C4D679_0049_FC:1:12:3317:1141 length=40
对于第四行的编码,最初由Phred程序的开发者定义,一般称为Phred qualitiy. 在Illumina早起版本(v1.3,v1.4)中,因为对quality的定义与Phred的不同,这行应该称为 Solexa quality。但从Illumina v1.5以后,也开始采用Phred的定义。
碱基质量得分是怎么来的?
Phred最初是一个从测序仪中产生的荧光记录数据中识别碱基的程序。在早起的荧光染料测序中,每次发生碱基合成时会释放出荧光信号,该信号被CCD图像传感器捕获。记录下荧光信号的峰值,生成一个实时的轨迹数据(chromatogram)。因为不同的碱基用不用的颜色标记,检测这些峰值即可判断出对应的碱基。但由于这些信号的波峰、密度、形状和位置等是不连续或模糊的,有时很难根据波峰判断出正确的碱基。
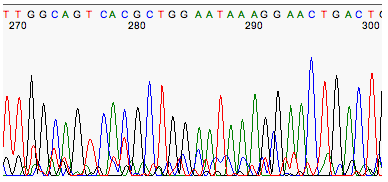
图1 chromatogram样图
Phred计算许多与波峰大小和分辨率相关的参数,根据这些参数,从一个巨大的查询表中找出碱基质量得分。这个查询表是根据对已知序列的测序数据分析得到的(应该是分析得到波峰参数与碱基错误率的关系,再通过公式把错误率转换成质量得分,得到波峰参数与质量得分的直接对应表)。不同的测序试剂和机器用不同的查询表。为了节约磁盘空间,质量得分(可能占用两个字符)按一定规则(Phred+33或Phred+64)被转换为单个字符表示。
碱基错误率与质量得分的关系有如下两种:
Qphred = -10log10p
Qillumina-prior to v.1.4 = -10log10(p/(1-p))
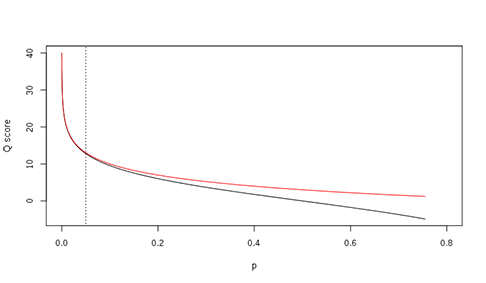
图 2 质量得分Q和错误率p的关系,红色的为phred,黑色的为Illumina早期版本,虚线表明p=0.05,对应的质量得分为Q≈13
在不同版本的编码中,除了质量得分与错误率有所差别外,在字符与得分的转换上也有差别。

图3 不同版本质量得分与质量字符ASCII值的关系
质量字符的ASCII值和质量得分的关系有如下两种:
Phred+64 质量字符的ASCII值 - 64
Phred+33: 质量字符的ASCII值 - 33
可以粗略分为 Phred+33和Phred+64,这里的33和64就是指ASCII值转换为得分该减去的数值。
在处理测序数据时,因为一些软件会根据碱基质量得分的不同做不同的处理,常要指定正确的编码方式,有必要对质量字符与质量得分的关系(Phred+33或Phred+64)作出正确的判断。当然,如果处理的是最近两年产生的测序数据,基本上都是Phred+33的,但从NCBI SRA数据库下载的旧数据就不一定了。
根据图3中Phred+33与Phred+64所使用的质量字符范围的不同,可以对fastq文件中质量得分的编码方式做出判断。图3中显示,ASCII值小于等于58(相应的质量得分小于等于25)对应的字符只有在Phred+33的编码中被使用,所有Phred+64所使用的字符的ASCII值都大于等于59。在通常情况下,ASCII值大于等于74的字符只出现在Phred+64中。利用这些信息即可在程序中进行判断。
文章末尾是一个对Phred+33或Phred+64做区分的perl脚本。
该脚本的判断思想如下:
默认读取1000条序列,在这1000条序列中:
1. 如果有2个以上的质量字符ASCII值小于等于58(即有两个碱基的得分小于等于25),同时没有任何质量字符的ASCII值大于等于75,即判断是Phred+33。
2. 如果有2个以上的质量字符ASCII值大于等于75(即有两个碱基的得分大于等于10),同时没有任何质量字符的ASCII值小于等于58,即判断是Phred+64。
3. 如果所有质量字符的ASCII值介于59到74之间,即判断可能是Phred+33,但建议使用更多的序列做进一步测试(出现这种结果可能有两种情况:1, Phred+33编码,所有碱基质量得分介于26到42之间;2,Phred+64编码,所有碱基质量得分介于-5到10;是前者的可能性大)。
4. 如果出现上述3种以外的情况,建议打印出质量字符的ASCII值人工判断。
理解错误的地方欢迎指正。
参考资料:
https://blog.sciencenet.cn/blog-630246-813262.html
上一篇:把CDS批量翻译为蛋白序列