博文
基于点对相似度的深度非松弛哈希算法
|
引用本文
汪海龙, 禹晶, 肖创柏. 基于点对相似度的深度非松弛哈希算法.自动化学报, 2021, 47(5): 1077-1086 doi: 10.16383/j.aas.c180571
Wang Hai-Long, Yu Jing, Xiao Chuang-Bai. Deep non-relaxing hashing based on point pair similarity. Acta Automatica Sinica, 2021, 47(5): 1077-1086 doi: 10.16383/j.aas.c180571
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c180571
关键词
哈希学习,非松弛,卷积神经网络,交叉熵
摘要
哈希学习能够在保持数据之间语义相似性的同时, 将高维数据投影到低维的二值空间中以降低数据维度实现快速检索. 传统的监督型哈希学习算法主要是将手工设计特征作为模型输入, 通过分类和量化生成哈希码. 手工设计特征缺乏自适应性且独立于量化过程使得检索的准确率不高. 本文提出了一种基于点对相似度的深度非松弛哈希算法, 在卷积神经网络的输出端使用可导的软阈值函数代替常用的符号函数使准哈希码非线性接近-1或1, 将网络输出的结果直接用于计算训练误差, 在损失函数中使用ℓ1范数约束准哈希码的各个哈希位接近二值编码. 模型训练完成之后, 在网络模型外部使用符号函数, 通过符号函数量化生成低维的二值哈希码, 在低维的二值空间中进行数据的存储与检索. 在公开数据集上的实验表明, 本文的算法能够有效地提取图像特征并准确地生成二值哈希码, 且在准确率上优于其他算法.
文章导读
近年来, 随着计算机软件和硬件技术的发展, 图像、视频等数据的维度和数量不断增加, 为了解决海量的高维数据的存储和检索问题, 研究学者提出了将高维数据投影到低维二值空间的哈希学习方法. 哈希学习方法是一种在保持图像或视频等高维数据间相似性的条件下, 通过哈希函数或函数簇将高维空间的数据投影到低维汉明空间的二值编码的机器学习方法. 通过哈希学习方法对数据建立索引, 提高图像等高维数据的检索效率, 并节省存储空间. 现有的哈希方法大致可以分为两类: 数据独立的方法和数据依赖的方法[1].
数据独立的方法使用随机投影来构造哈希函数. 局部敏感哈希(Locality sensitive hashing, LSH)算法[2-4]于1998年由Indyk等提出, 该算法在原始空间中使用随机线性投影将距离近的数据投影到相似的二值编码中. 该算法的哈希函数简单易实现, 计算速度快, 但准确率不高. 核化局部敏感哈希(Kernelized locality-sensitive hashing, KLSH)算法[5]对LSH算法提出了改进, KLSH在核空间中随机构造哈希函数, 不需要考虑原始空间的数据分布, 可以选择任意核函数作为相似性度量函数. 但由于核函数的引入, 很大程度上增加了计算复杂度. 数据独立的方法虽然简单易实现, 但是由于这类方法不使用训练数据训练模型, 所以需要很长的哈希码才能达到较高的准确率. 数据依赖的方法使用训练数据来学习将高维数据投影为低维二值编码的哈希函数. 如同一般的机器学习方法, 数据依赖的方法可以分为非监督型方法和监督型方法.
非监督型哈希学习方法是在数据没有类别信息或不利用类别信息情况下, 根据某种距离度量检索最近邻数据的方法. 谱哈希(Spectral hashing, SH)算法[6]是一种典型的非监督哈希算法, 其采用主成分分析(Principal component analysis, PCA)算法[7]获取图像数据的各个主成分方向, 并计算所有的解析特征函数(Analytical eigenfunction), 然后使用符号函数将这些解析特征函数的值量化为二值编码. 由于在实际情况中很难同时满足谱哈希的两个约束条件, 即假设从多维均匀分布的空间中采样数据以及不同维度上的哈希编码之间相互独立, 因此谱哈希的使用受到一定限制. 迭代量化哈希(Iterative quantization, ITQ)算法[8]将数据投影到中心为零(Zero-centered)的二值超立方体(Binary hypercube)的顶点, 使得投影后的数据与原数据之间的量化误差能够最小化, 并使用一种简单有效的交替最小化(Alternating minimization)方法求解目标函数. 与SH算法相比, ITQ算法不仅应用范围更广, 而且经实验验证ITQ算法的检索效果更好.
监督型哈希学习方法是指将图像或其他高维数据的类别标签用于估计二值编码模型的输出, 在迭代过程中不断利用图像的标签信息计算实际输出与预期输出之间的误差反馈给模型, 不断调整模型参数的方法. 由于监督型哈希方法利用了数据的标签信息, 一般情况, 监督型哈希方法的效果比非监督性哈希方法的效果好. 2011年, Norouzi等提出了最小损失哈希(Minimal loss hashing, MLH)算法[9], 这是一种典型的监督型哈希学习算法, 该算法通过结构化支撑向量机(Structural support vector machine, Structural SVM)建立损失函数, 由于损失函数不连续且非凸, 难以直接求解, 该算法通过构造并最小化损失函数的上界来求解损失函数. 基于核的监督哈希(Kernel-based supervised hashing, KSH)算法[10]采用核的形式来构造哈希函数, 使得其泛化可以处理非线性可分的问题, 并且, 不同于MLH算法的是, KSH算法不直接通过最小化哈希码之间的汉明距离来学习哈希函数, 而是通过最小化哈希码的内积, 使问题变得更简单, 更容易求解. 2015年, Shen等[11]提出了监督型离散哈希(Supervised discrete hashing, SDH)算法, 该算法使用Lagrange乘子法将离散约束问题松弛为凸优化问题, 在求解阶段使用循环坐标下降法(Cyclic coordinate descent, DCC)求解目标函数, 即每次迭代固定其他的哈希位, 只将一个哈希位作为变量求解, SDH算法在保持准确率的同时, 提高了算法的效率.
上述传统的哈希学习方法在提取图像特征时采用手工设计特征, 例如梯度方向直方图(Histogram of oriented gradient, HOG)、尺度不变特征变换(Scale invariant feature transform, SIFT)等, 不同场景的图像使用相同的手工设计特征在一定程度上影响了哈希学习算法的性能, 单一的特征导致检索准确率不高. 近年来, 卷积神经网络(Convolutional neural network, CNN)[12-13]在计算机视觉领域成为主要的特征学习工具, 在图像分类[14]、目标检测[15-16]等方向得到广泛应用. 目前许多学者也尝试将CNN用于哈希学习方法中, 陆续出现了一些深度哈希学习方法.
2014年, Xia等[17]提出了卷积神经网络哈希(Convolutional neural network hashing, CNNH)算法, 该算法利用深层框架来学习图像的特征, 然后以此特征学习哈希函数. 这是一种两阶段哈希学习算法, 第1阶段通过对相似度矩阵进行分解, 预生成样本的二值编码; 第2阶段将样本数据输入CNN, 使用卷积层提取图像特征, 通过最小化网络输出值与第1阶段预编码之间的误差, 获得样本的哈希码. CNNH相对于非深度哈希学习算法在准确率上有明显的提高, 然而也存在明显的问题, 第1阶段中相似度矩阵分解是一个非凸优化问题, 分解过程中需要大量的松弛方法, 导致准确率会受到很大的影响; 第2阶段仅利用了CNN自动提取图像特征, 没有参与第1阶段的计算. 基于监督型深度哈希的快速图像检索(Deep supervised hashing for fast image retrieval, DSH)算法[18]利用成对的图像和图像的标签作为网络的输入进行训练, 并联合使用对比损失函数(Contrastive loss)与哈希码的ℓ1范数正则项作为网络的损失函数, 以此约束哈希码, 使输出在汉明空间的哈希码更加多样化, 避免了两阶段哈希算法中第1阶段不能利用CNN网络, 以及使用sigmoid函数导致网络收敛速度过慢的问题. 2016年, Li等[19]提出了基于标签对的监督型深度哈希特征学习(Feature learning based deep supervised hashing with pairwise labels, DPSH)算法, 该算法通过图像的类别标签构造图像的标签对矩阵, 根据图像的标签对构建交叉熵损失函数, 以此衡量深度卷积神经网络训练的损失, 使用基于Lagrange乘子法的松弛优化方法, 对约束条件进行松弛, 去掉符号函数的约束条件, 解决离散约束问题. 但是由于该算法使用Lagrange乘子, 某些哈希位会被过度松弛, 导致相似点对之间的语义信息保留不完整. 连续深度哈希学习(Deep learning to hash by continuation, HashNet)算法[20]也使用图像的标签对构建目标损失函数, 该算法在目标函数构造过程中引入加权似然函数, 有效地解决了相似点对数据不平衡问题, 同时在网络的输出端使用尺度双曲正切函数(Scaled tanh function)对网络输出进行阈值化, 并在迭代过程中, 不断增大尺度系数, 使其逼近符号函数的功能. 从实验结果来看, 与传统的哈希学习方法相比, 监督型深度哈希学习方法在准确率方面明显胜过传统的方法.
本文提出了一种基于点对相似度的深度非松弛哈希(Deep non-relaxing hashing based on point pair similarity, DNRH)算法, 该算法使用交叉熵保持相似点对之间的语义相似性, 在卷积神经网络的输出端使用一种软阈值函数阈值化网络输出得到准哈希码, 并使用ℓ1范数约束输出端的准哈希码, 使得准哈希码的绝对值逼近1, 避免了Lagrange乘子的松弛求解对模型准确率的影响. 本文利用卷积神经网络提取图像的特征表示并学习哈希函数生成哈希码, 这样就避免了相似度矩阵分解的不准确对后续量化过程的影响. 综上所述, 本文的主要贡献归纳如下:
1) 在损失函数中引入ℓ1范数约束输出端的准哈希码, 通过正则项约束准哈希码, 使其各哈希位的绝对值逼近1.
2) 为了减小量化误差, 在CNN的输出端使用软阈值函数, 使输出的准哈希码非线性地接近-1或1. 在模型外部使用符号函数sgn(⋅), 将准哈希码量化为二值哈希码.
本文后续结构组织如下: 第1节介绍本文算法的背景, 第2节描述本文算法的模型、求解以及网络结构, 第3节通过实验验证本文算法的性能, 第4节为全文结论.
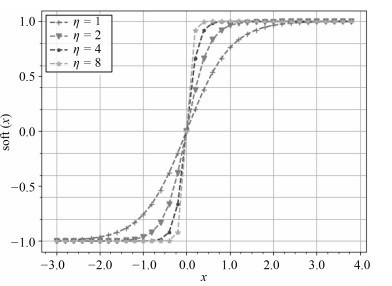
图 1 soft(x)的函数曲线
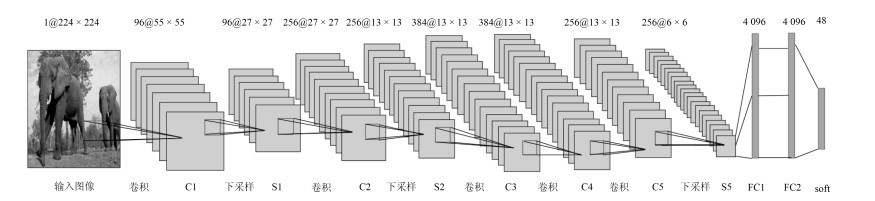
图 2 本文算法使用的网络模型
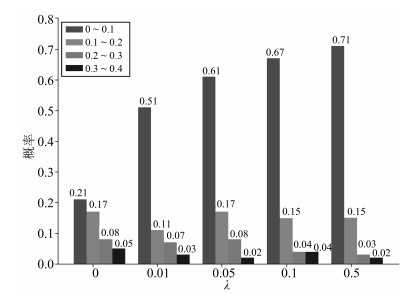
图 3 不同正则项系数λ下准哈希码的分布
本文提出了一种基于点对相似度的深度非松弛哈希学习算法, 该算法通过CNN自动提取图像特征, 在目标函数中使用交叉熵保持相似点对之间的语义相似性, 在CNN输出端使用可导的软阈值函数代替传统方法中的符号函数, 使准哈希码非线性地接近-1或1. 并在损失函数中引入ℓ1范数约束输出的准哈希码, 使得准哈希码逼近二值编码. 最终在训练好的模型外部使用符号函数, 将准哈希码量化为二值哈希码. 在公开数据集(CIFAR-10、NUS-WIDE)上的实验验证了本文提出的DNRH算法优于其他哈希学习算法, 取得了令人满意的效果.
作者简介
汪海龙
北京工业大学信息学部硕士研究生. 主要研究方向为图像处理与机器学习. E-mail: 18810815820@163.com
禹晶
北京工业大学信息学部副教授. 2011年获清华大学电子工程系博士学位. 主要研究方向为图像处理与模式识别. E-mail: jing.yu@bjut.edu.cn
肖创柏
北京工业大学信息学部教授. 主要研究方向为数字信号处理, 音视频信号处理与网络通信. 本文通信作者. E-mail: cbxiao@bjut.edu.cn
https://blog.sciencenet.cn/blog-3291369-1352868.html
上一篇:基于胰岛素基础率估计的人工胰腺系统自抗扰控制
下一篇:基于状态集员估计的主动故障检测