博文
基于隐私保护的联邦推荐算法综述
|
引用本文
张洪磊, 李浥东, 邬俊, 陈乃月, 董海荣. 基于隐私保护的联邦推荐算法综述. 自动化学报, 2022, 48(9): 2142−2163 doi: 10.16383/j.aas.c211189
Zhang Hong-Lei, Li Yi-Dong, Wu Jun, Chen Nai-Yue, Dong Hai-Rong. A survey on privacy-preserving federated recommender systems. Acta Automatica Sinica, 2022, 48(9): 2142−2163 doi: 10.16383/j.aas.c211189
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c211189
关键词
推荐系统,联邦学习,隐私保护,协同过滤
摘要
推荐系统通过集中式的存储与训练用户对物品的海量行为信息以及内容特征, 旨在为用户提供个性化的信息服务与决策支持. 然而, 海量数据背后存在大量的用户个人信息以及敏感数据, 因此如何在保证用户隐私与数据安全的前提下分析用户行为模式成为了近年来研究的热点. 联邦学习作为新兴的隐私保护范式, 能够协调多个参与方通过模型参数或者梯度等信息共同学习无损的全局共享模型, 同时保证所有的原始数据保存在用户的终端设备, 较之于传统的集中式存储与训练模式, 实现了从根源上保护用户隐私的目的, 因此得到了众多推荐系统领域研究学者们的广泛关注. 基于此, 对近年来基于联邦学习范式的隐私保护推荐算法进行全面综述、系统分类与深度分析. 具体的, 首先综述经典的推荐算法以及所面临的问题, 然后介绍基于隐私保护的推荐系统与目前存在的挑战, 随后从多个维度综述结合联邦学习技术的推荐算法, 最后对该方向做出系统性的总结并对未来研究方向与发展趋势进行展望.
文章导读
随着移动互联网络的飞速发展, 人们所持有的用户设备逐渐多元化, 进而使得用户能够越来越便捷上传所生成的内容数据, 因此海量用户行为与内容数据由此产生. 另外, 随着计算机硬件与人工智能技术的持续进步, 出色的计算能力与大规模算法模型也为海量数据的产生与处理提供了先决条件. 然而, 互联网产生数据的速度远远超过用户所能处理数据的速度, 以至于造成用户不能及时运用有效信息的情况, 这就产生了信息生产者与内容消费者之间的尖锐矛盾, 最终导致信息过载现象的发生[1].
推荐系统作为缓解信息过载问题的有效途径[2], 其通过利用用户与物品的历史交互数据以及各自固有的内容属性特征进行个性化建模以此实现对于用户未来可能感兴趣的物品进行精准预测的功能, 因而该技术得到了许多学者们的广泛关注[3]. 并且由于其巨大的商业价值, 推荐算法也在工业界在线平台上(比如社交[4]、新闻[5]、购物[6]等)成为了必不可少的重要组件. 推荐系统根据其推荐原理以及所利用具体数据的不同, 可进一步划分为利用属性信息的基于内容的方法[7]、利用用户对物品历史行为信息的协同过滤方法[8]以及利用多种信息源的混合推荐方法. 近年来, 由于深度学习出色的表示能力, 基于深度学习的推荐算法[9]能够高效利用海量训练样本, 并且能够有效整合多种附加信息(比如社交信息[10]、文本信息[11]、图像信息[12]等), 以此缓解推荐系统固有的数据稀疏与冷启动问题[13].
然而, 融合用户大量个人信息固然可以提升推荐算法的预测精度, 但往往会对用户的隐私和数据安全问题产生担忧. 具体地, 文献[14-16]表明仅利用用户所产生的内容数据或者历史行为信息可以反推出用户的敏感属性特征, 另外引入社交网络等附加信息可以实现更低成本的隐私泄露. 由于海量信息中不可避免的存在用户个人数据以及敏感信息, 因此平台需要收集更多的训练数据以提升推荐性能与用户为保护隐私而尽可能少的共享个人数据间的矛盾逐渐凸显. 另外, 随着中国对于数据安全与隐私问题越来越重视, 因此, 如何在保证用户隐私和安全的前提下有效融合更多数据以提升推荐性能成为了数据挖掘领域关注的重点. 所以, 基于隐私保护的推荐算法逐渐得到大家的广泛关注[17-19].
传统的隐私保护推荐算法主要采用差分隐私等机制添加数据扰动[20]或者利用加密的方式(比如同态加密[21]与安全多方计算[22]等)实现对于个人敏感信息的隐私保护. 然而添加扰动的方法需要严格的数学假设并且不可避免的对原始数据引入偏差, 而加密的方式虽然能够实现对于原始数据的无损保护, 但加密操作往往需要更大的计算量最终使得模型的实时性大打折扣. 值得一提的是, 上述传统隐私保护推荐算法需要将个人数据收集到中心服务端进行存储与训练, 因此在原始数据传输等过程中仍然存在隐私泄露与安全威胁的问题. 另外, 由于上述隐私与安全问题的担忧造成了多参与方不能安全高效的进行数据共享, 最终导致数据孤岛现象进而影响整体模型的预测性能.
得益于近年来分布式学习与边缘计算的飞速发展, 以及互联网生态逐渐移动化与开放化, 使得用户终端设备有能力存储并训练相当容量的数据. 联邦学习[23]充分发挥终端设备的计算能力并协同服务端联合优化全局模型, 同时能够使得原始数据保留在本地而较好地保护用户隐私信息, 这一新兴的隐私保护范式逐渐得到大家的认可[24]. 另外, 由于推荐系统的数据来源存在天然的分布式特性, 以及用户对于推荐服务严苛的实时性要求, 因此近年来端云架构下结合联邦学习的推荐算法取得了较大的进展[25-32]. 然而, 目前国内相关文献缺乏对于此研究方向的细致梳理与归纳总结. 基于以上动机, 本文对联邦学习赋能的推荐系统进行了全面综述, 细致整理了近3年发表在相关领域会议和期刊中此方向的文献, 旨在为该领域梳理出一条清晰的研究脉络, 为基于隐私保护的推荐算法提供更加全面的理论基础与研究框架(对于本文所收集的论文列表可访问链接https://github.com/hongleizhang/RSPapers).
本文第1节对推荐模型的发展历程进行分类介绍, 结构如下: 包括传统推荐算法、基于深度学习的推荐算法以及基于隐私保护的推荐算法. 第2节详细阐述基于联邦学习范式的隐私保护推荐算法的基本框架并对其扩展工作进行分类介绍. 第3节介绍联邦推荐系统所使用的开源工具库以及用于实验评估的常用数据集. 第4节总结本文并分析现有方法存在的问题并对未来可能的研究方向和发展趋势加以展望.

图1 主流推荐模型发展历程
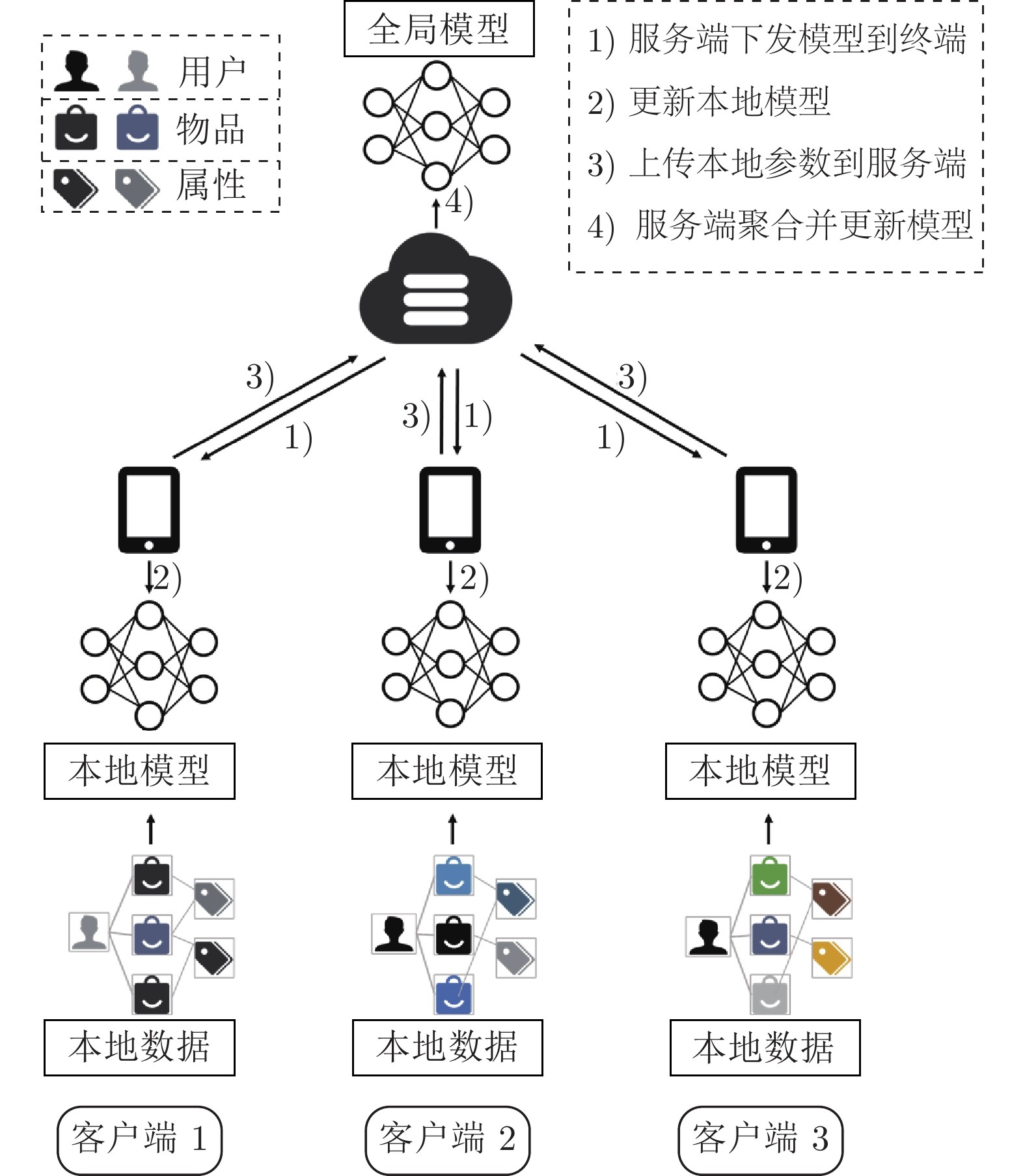
图2 联邦推荐系统训练流程图
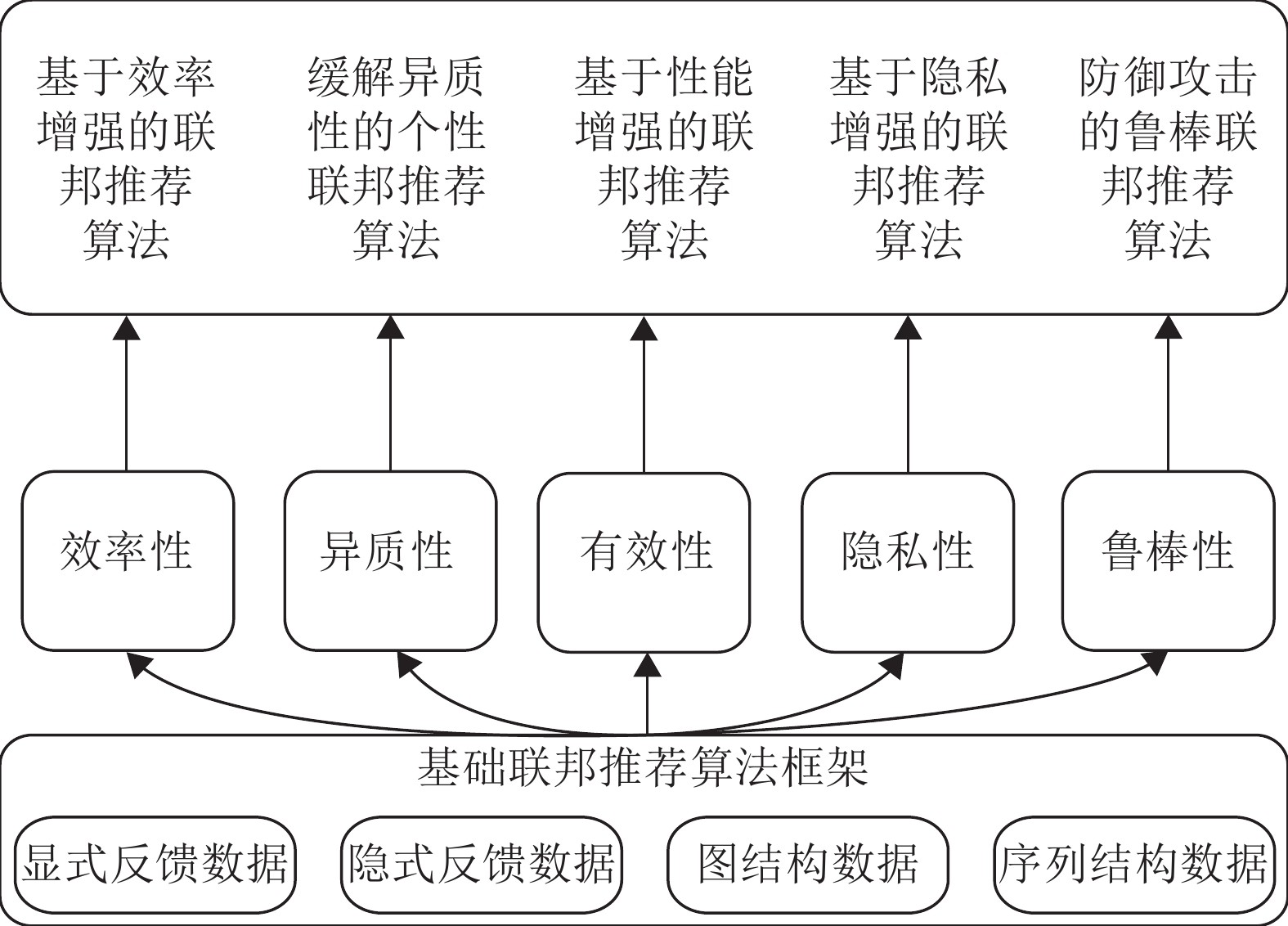
图3 联邦推荐系统研究方向总结
本文首先对近年来推荐系统领域的研究进展进行了综述, 并按照传统推荐算法、基于深度学习的推荐算法以及基于隐私保护的推荐算法进行了详细分类介绍. 其中, 基于隐私保护的推荐算法根据其所利用原理的不同分为了匿名化方法、数据扰动方法、密码学方法、对抗学习方法, 并对其进行详细介绍. 最后系统性的综述了联邦学习与推荐系统领域相结合的最新研究进展, 首先介绍了联邦学习以及联邦推荐系统的定义, 随后按照基础联邦学习推荐算法框架、基于效率增强的联邦推荐算法、缓解异质性的个性化联邦推荐算法、基于性能增强的联邦推荐算法、基于隐私增强的联邦推荐算法以及防御攻击的鲁棒联邦推荐算法6个方面进行详细介绍. 最后详细介绍和总结了该方向常用的开源工具库以及经典数据集, 以此便于对基于联邦学习的推荐系统领域进行实验评估.
通过对基于隐私保护的联邦推荐算法进行全面的调研与综述, 发现当前的研究成果已经在一定程度上保护了用户敏感数据的隐私安全同时保障了推荐模型的预测精度, 但仍然存在如下的研究难点与热点.
1)联邦推荐系统的激励机制. 激励机制旨在建立一个公平高效的平衡机制使得各参与方能够持续地参与到联邦学习的全生命周期中, 以此最大化集合体的全局效用且最小化各参与方的局部损失与训练成本. 不同于其他联邦学习应用场景, 联邦推荐系统中的客户端代表真实的用户个体, 因此如何评估每个用户的模型训练贡献以及如何设计高效的调度算法以此持续激励用户进行数据共享和提供客户端算力是目前具有潜力的研究方向.
2)联邦推荐系统的冷启动挑战. 冷启动问题是指新用户或者新物品在进入既有系统时存在的交互数据稀缺的情况. 集中式推荐模型的冷启动问题已经形成了较为全面的研究体系. 然而, 由于联邦推荐系统场景下的冷启动问题更具有挑战性, 比如如何在资源受限的联邦设置下融合并建模更多有效的附加信息来缓解终端用户的数据稀疏问题, 因此当前的研究工作还处于初级阶段.
3)联邦推荐系统的异质性挑战. 异质性在传统联邦学习设置中已经进行了广泛的研究, 主要体现在数据异质性与模型异质性方面. 在推荐系统场景中由于参与方为真实的用户个体使得异质性更加具有挑战性, 比如个人行为数据存在严重的特征偏斜情况以及所参与的用户设备数量众多且设备各异等问题, 因此如何在联邦学习框架下细粒度的建模数据异质性以及模型异质性是目前推荐系统领域的主要挑战.
4)联邦推荐系统的实时性挑战. 实时性是保障机器学习系统能够稳定部署在真实场景中的重要指标, 其主要体现在模型的更新周期以及部署效率上. 集中式推荐模型由于可以在计算能力以及存储能力更强的服务器端完成实时的模型训练以及线上更新, 使得用户兴趣能够及时被推荐模型捕捉. 然而联邦推荐系统在集中式推荐模型挑战的基础上还要重点关注模型参数在服务端与用户终端间的上传与下载的传输时延等复杂情况, 因此如何提高模型参数的传输效率以及优化本地模型的更新机制以此来提高联邦推荐模型的实时性有利于进一步改善联邦推荐场景的用户体验.
作者简介
张洪磊
北京交通大学计算机与信息技术学院博士研究生. 主要研究方向为推荐系统与隐私保护. E-mail: honglei.zhang@bjtu.edu.cn
李浥东
北京交通大学计算机与信息技术学院教授. 主要研究方向为大数据分析与安全, 数据隐私保护与先进计算. E-mail: ydli@bjtu.edu.cn
邬俊
北京交通大学计算机与信息技术学院副教授. 主要研究方向为信息检索与推荐系统. E-mail: wuj@bjtu.edu.cn
陈乃月
北京交通大学计算机与信息技术学院讲师. 主要研究方向为社交网络, 数据挖掘与联邦学习. 本文通信作者. E-mail: nychen@bjtu.edu.cn
董海荣
北京交通大学轨道交通控制与安全国家重点实验室教授. 主要研究方向为列车运行智能控制与优化和调度控制一体化. E-mail: hrdong@bjtu.edu.cn
https://blog.sciencenet.cn/blog-3291369-1356316.html
上一篇:基于轻量化重构网络的表面缺陷视觉检测
下一篇:一种基于DTW-GMM的机器人多机械臂多任务协同策略