博文
结合目标检测的人体行为识别
|
引用本文
周波, 李俊峰. 结合目标检测的人体行为识别. 自动化学报, 2020, 46(9): 1961−1970 doi: 10.16383/j.aas.c180848
Zhou Bo, Li Jun-Feng. Human action recognition combined with object detection. Acta Automatica Sinica, 2020, 46(9): 1961−1970 doi: 10.16383/j.aas.c180848
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c180848
关键词
深度学习,行为识别,卷积神经网络,机器视觉,目标检测
摘要
人体行为识别领域的研究方法大多数是从原始视频帧中提取相关特征, 这些方法或多或少地引入了多余的背景信息, 从而给神经网络带来了较大的噪声. 为了解决背景信息干扰、视频帧存在的大量冗余信息、样本分类不均衡及个别类分类难的问题, 本文提出一种新的结合目标检测的人体行为识别的算法. 首先, 在人体行为识别的过程中增加目标检测机制, 使神经网络有侧重地学习人体的动作信息; 其次, 对视频进行分段随机采样, 建立跨越整个视频段的长时时域建模; 最后, 通过改进的神经网络损失函数再进行行为识别. 本文方法在常见的人体行为识别数据集UCF101和HMDB51上进行了大量的实验分析, 人体行为识别的准确率(仅RGB图像)分别可达96.0%和75.3%, 明显高于当今主流人体行为识别算法.
文章导读
目前, 人体行为分析成为一个十分活跃的计算机视觉领域, 包括对剪辑与未剪辑的视频段进行动作识别、时序动作提名、检测等研究方向分支. 人体行为识别在物联网与大数据的环境下具有广阔的应用场景, 包括体育运动、智能交通、虚拟现实、人机交互等领域. 由于人体行为的高复杂性与场景的多变化性[1], 使得行为识别成为一项非常具有挑战性的课题.
得益于卷积神经网络(Convolutional neural network, CNN)在图像处理领域取得的巨大成就以及大数据的发展, 目前基于深度学习的人体行为识别的方法[2-5]已经优于基于经典的手工设计特征的方法[6-10], 且在三维空间的动作识别[11-14]领域也取得了显著成效.
然而, 基于深度学习的人体行为识别方法仍然存在一些难点[15]: 首先, Karpathy等[16]将单幅RGB图像作为深度学习模型的输入, 只考虑了视频的空间表观特征, 而忽视了视频与单幅静态图像的区别, 没有对视频的时域信息进行编码. 对此, Ji等[17]首次使用3D-CNN来获得运动信息; Donahue等[18]利用2D-CNN提取视频帧的表征信息, 紧接着连接一个长短期记忆(Long short-term memory, LSTM)循环神经网络或者GRU (Gated recurrent unit)等来学习帧与帧之间的运动信息[19]; 与Donahue等[18]的做法不同, Zolfaghari等[20]将2D-CNN之后的循环神经网络替换成了3D-CNN. Simonyan等[21]首次提出结合RGB图像与光流图像的双流卷积神经网络的方法, 利用视频相邻帧之间的信息差计算出光流作为网络的输入, 以期获得视频的时域信息. 后来的研究[22] 也表明: RGB与光流的方法相融合可以提高在测试集上的精度. 对于RGB+光流的做法, 计算光流耗时也占用了计算机的额外内存. 所以, Tran等[23]提出一种基于3D-CNN的新的网络结构, 以期在单一网络中同时对视频的空域和时域信息进行编码, 而3D-CNN相比于2D-CNN的计算量较大.
其次, 不论是2D-CNN中堆叠的光流或是3D-CNN中堆叠的RGB图像, 都只对视频进行短期的时域信息编码, 尚未考虑视频的长时时域信息. 例如, 在一段视频中, 一个动作延续时间通常是几秒至几十秒甚至更长. 对此, Wang等[24]提出了时间段网络(Temporal segment network, TSN), 一个输入视频被分为K段(segment), 而一个片段(snippet)从它对应的段中随机采样得到. 不同片段的类别得分采用段共识函数(Segmental consensus function)进行融合来产生段共识(segmental consensus). 最后对所有模型的预测融合产生最终的预测结果.
另外, 针对视频中相邻两帧差异很小的情况, Zolfaghari等[20]提出ECO (Efficient convolutional network for online video understanding)以避免过多计算视频帧中的冗余信息, 从而实现实时动作识别. He等[25]为了提升模型在数据集上的准确度, 提出结合RGB图像、光流、音频信息的多模态融合方法, 此方法精度稍高但却十分占用计算空间与资源.
为了让CNN更好地学习到视频中的动作信息, 受目标检测算法的启发, 本文将区域候选网络(Region proposal network, RPN)应用于算法中, 将视频中人所在区域精确地提取出来, 变换到原图像大小, 以此作为神经网络的输入. 考虑到图像经过目标检测算法后得出的目标区域必定大小不一, 对此, 在本文算法中, 对每一幅图片做对齐操作, 确保输入到网络的图片大小一致. 此外, 类似于TSN, 本文还对视频片段进行分段稀疏采样以使模型获得视频级的表达能力, 并将用于分类的交叉熵函数改进为Lin等[26]提出的焦点损失(Focal loss)函数, 以解决分类问题中类别判断难以及可能存在的样本不均衡问题.
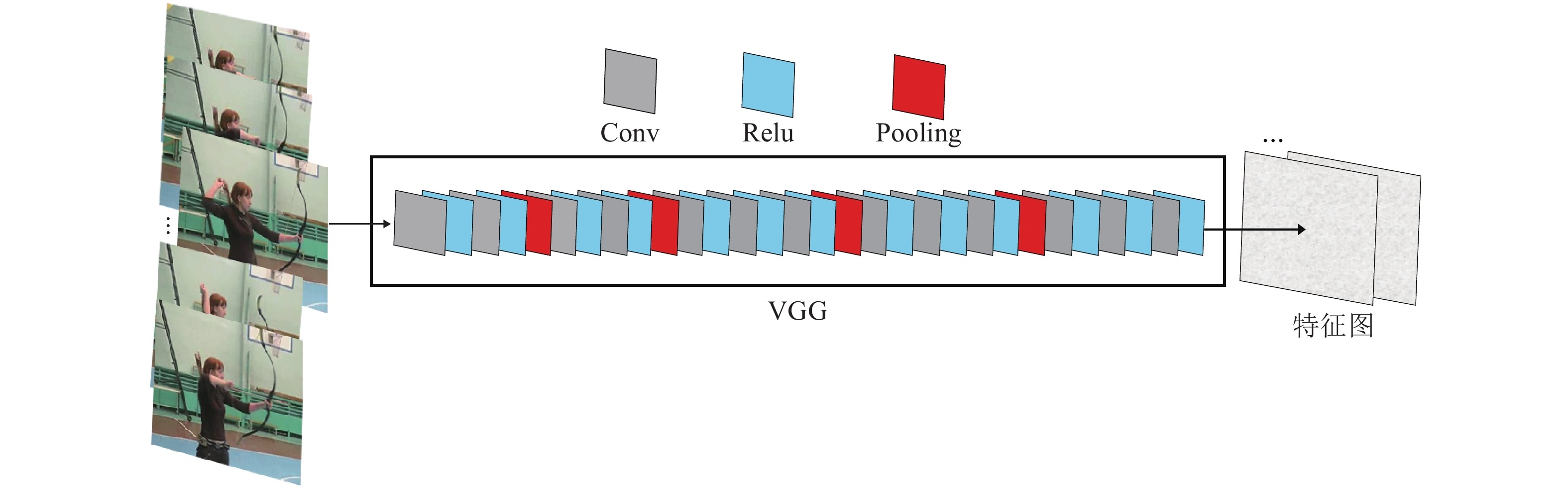
图 1 VGG特征提取器
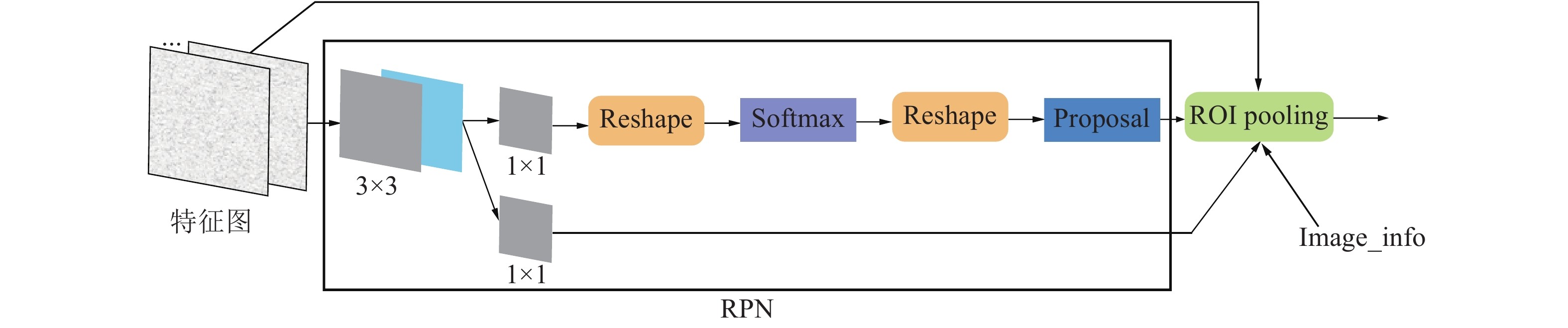
图 2 区域候选网络

图 3 边框回归与类别预测
本文提出了一种结合目标检测的人体行为识别方法. 通过在人体行为识别算法中加入目标检测机制, 使神经网络能够有侧重地学习人体的动作信息, 而减弱部分不必要的背景噪声干扰, 同时对不合要求的图像进行替换, 达到平衡背景取舍的作用. 结合视频分段随机采样, 改进I3D网络的损失函数. 本文提出的算法在常用数据集上进行实验, 并与其他先进算法进行比较, 体现出了良好的性能, 实验结果验证了本文提出方法的有效性.
作者简介
周波
浙江理工大学硕士研究生. 2017年获浙江理工大学机械与自动控制学院学士学位. 主要研究方向为深度学习, 计算机视觉与模式识别. E-mail: zhoubodewy@163.com
李俊峰
浙江理工大学机械与自动控制学院副教授. 2010年获得东华大学工学博士学位. 主要研究方向为图像质量评价, 人体行为识别, 产品视觉检测. 本文通信作者. E-mail: ljf2003@zstu.edu.cn
https://blog.sciencenet.cn/blog-3291369-1375503.html
上一篇:渐近非局部平均图像去噪算法
下一篇:【IEEE/CAA JAS虚拟专题】非线性系统