博文
自适应特征融合的多模态实体对齐研究
|
引用本文
郭浩, 李欣奕, 唐九阳, 郭延明, 赵翔. 自适应特征融合的多模态实体对齐研究. 自动化学报, 2024, 50(4): 758−770 doi: 10.16383/j.aas.c210518
Guo Hao, Li Xin-Yi, Tang Jiu-Yang, Guo Yan-Ming, Zhao Xiang. Adaptive feature fusion for multi-modal entity alignment. Acta Automatica Sinica, 2024, 50(4): 758−770 doi: 10.16383/j.aas.c210518
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c210518
关键词
多模态知识图谱,实体对齐,预训练模型,特征融合
摘要
多模态数据间交互式任务的兴起对于综合利用不同模态的知识提出了更高的要求, 因此融合不同模态知识的多模态知识图谱应运而生. 然而, 现有多模态知识图谱存在图谱知识不完整的问题, 严重阻碍对信息的有效利用. 缓解此问题的有效方法是通过实体对齐进行知识图谱补全. 当前多模态实体对齐方法以固定权重融合多种模态信息, 在融合过程中忽略不同模态信息贡献的差异性. 为解决上述问题, 设计一套自适应特征融合机制, 根据不同模态数据质量动态融合实体结构信息和视觉信息. 此外, 考虑到视觉信息质量不高、知识图谱之间的结构差异也影响实体对齐的效果, 本文分别设计提升视觉信息有效利用率的视觉特征处理模块以及缓和结构差异性的三元组筛选模块. 在多模态实体对齐任务上的实验结果表明, 提出的多模态实体对齐方法的性能优于当前最好的方法.
文章导读
近年来, 以三元组形式表示现实世界知识或事件的知识图谱逐渐成为一种主流的结构化数据的表示方式, 并广泛应用于各类人工智能的下游任务, 如知识问答[1]、信息抽取[2]、推荐系统[3]等. 相比于传统的知识图谱, 多模态知识图谱[4-5]将多媒体信息融合到知识图谱中, 从而更好地满足多种模态数据之间的交互式任务, 例如图像和视频检索[6]、视频摘要[7]、视觉常识推理[8]和视觉问答[9]等, 并在近年来受到了学界及工业界的广泛关注.
现有的多模态知识图谱往往从有限的数据源构建而来, 存在信息缺失、覆盖率低的问题, 导致知识利用率不高. 考虑到人工补全知识图谱开销大且效率低, 为提高知识图谱的覆盖程度, 一种可行的方法[10-12]是自动地整合来自其他知识图谱的有用知识, 而实体作为链接不同知识图谱的枢纽, 对于多模态知识图谱融合至关重要. 识别不同的多模态知识图谱中表达同一含义的实体的过程, 称为多模态实体对齐[5, 13].
与一般的实体对齐方法不同[11, 14], 多模态实体对齐需要利用和融合多个模态的信息. 当前主流的多模态实体对齐方法[5, 13]首先利用图卷积神经网络学习知识图谱的结构信息表示; 然后利用预训练的图片分类模型, 生成实体的视觉信息表示(利用VGG16[15]、ResNet[16]生成多张图片向量并加和), 得到实体的视觉信息表示; 最后以特定权重将这两种模态的信息结合. 不难发现, 这类方法存在以下3个明显缺陷:
1) 图谱结构差异性难以处理. 不同知识图谱中对等的实体通常具有相似的邻接信息, 基于这一假设, 目前的主流实体对齐方法主要依赖知识图谱的结构信息[14, 17-18]来实现对齐. 然而真实世界中, 由于构建方式的不同, 不同知识图谱可能存在着较大结构差异, 这不利于找到潜在的对齐实体. 如图1所示, 实体 [The dark knight] 在 DBpedia 和 FreeBase 中邻接实体数量存在巨大差异, 虽然包含相同的实体[Nolan]、[Bale], 然而在FreeBase还包含额外6个实体. 因此, DBpedia 中的实体 [Bale]容易错误地匹配到 FreeBase 中的实体 [Gary oldman], 因为它们都是[The dark knight]的邻居实体且度数为 1. 真实世界中不同知识图谱的结构性差异问题比图中的示例更为严峻, 以数据集MMKG[5]为例, 基于FreeBase抽取得到的图谱 (FB15K)有接近60万的三元组, 而基于DBpedia抽取得到的图谱(DB15K)中三元组数量不足10万. 以实体[Nolan]为例, 在FB15K中有成百的邻居实体; 而DB15K中其邻居实体数量不足10个. 针对此类问题, 可基于链接预测生成三元组以丰富结构信息. 这虽然在一定程度上缓和了结构差异性, 但所生成的三元组的可靠性有待考量. 此外, 在三元组数量相差多倍的情况下补全难度很大.
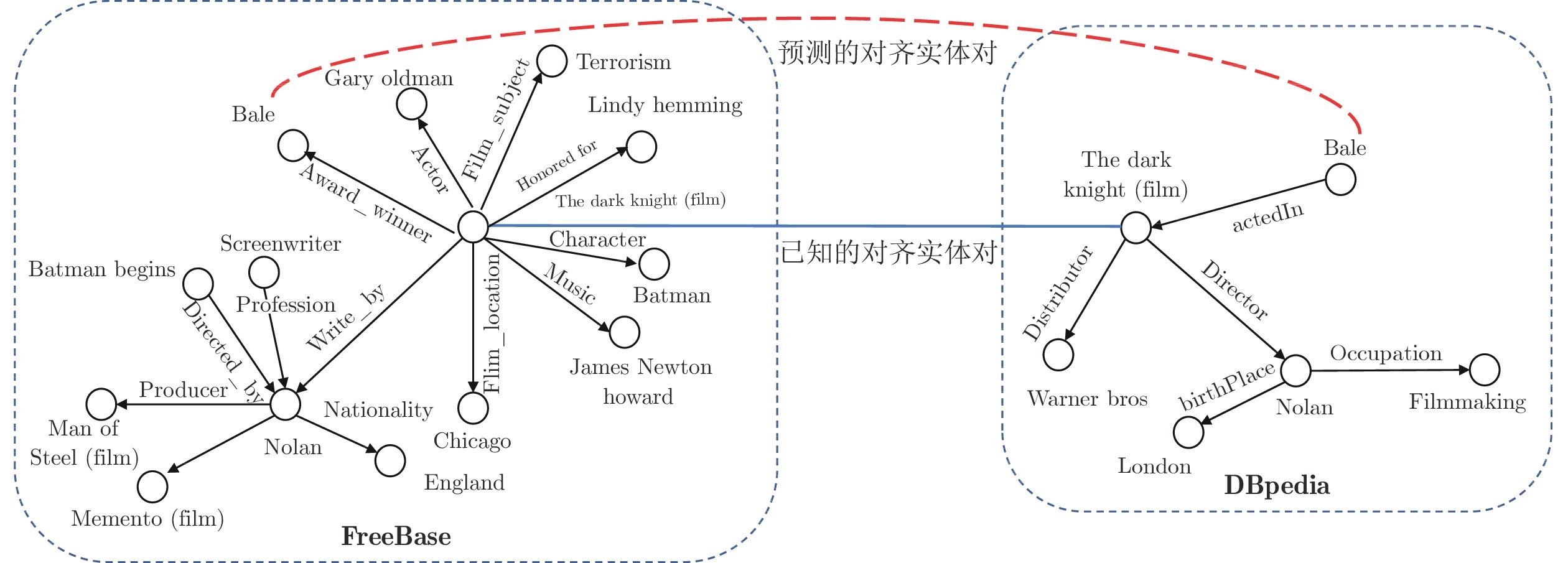
图 1 知识图谱FreeBase和DBpedia的结构差异性表现
2) 视觉信息利用差. 当前自动化构建多模态知识图谱的方法通常基于现有知识图谱补充其他模态的信息, 为获取视觉信息, 通常利用爬虫从互联网爬取实体的相关图片以获取其视觉信息. 然而获取的结果中不可避免地存在部分相关程度较低的图片, 即噪声图片. 现有方法[5, 13, 19]忽略了噪声图片的影响, 使得基于视觉信息对齐实体的准确率受限. 因此, 实体的视觉信息中混有部分噪声, 进而降低了利用视觉信息进行实体对齐的准确率.
3) 多模态融合权重固定. 当前的主流多模态实体对齐方法[5, 13]以固定的权重结合多个模态. 这类方法假设多种模态信息对实体对齐的贡献率始终为一固定值, 并多依赖于多模态知识图谱的结构信息, 然而其忽略了不同模态信息的互补性. 此外, 由于实体相关联的实体数量以及实体在图谱中分布不同, 导致不同实体的结构信息有效性存在一定的差异, 进一步影响不同模态信息的贡献率权重. 事实上, 知识图谱中超过半数实体都是长尾实体[20], 这些实体仅有不足5个相连的实体, 结构信息相对匮乏. 而实体的视觉信息却不受结构影响, 因此在结构信息匮乏的情况下应赋予视觉信息更高的权重. 总而言之, 以固定的权重结合多模态信息无法动态调节各个模态信息的贡献率权重, 导致大量长尾实体错误匹配, 进一步影响实体对齐效果.
为解决上述缺陷, 本文创新性地提出自适应特征融合的多模态实体对齐方法(Adaptive feature fusion for multi-modal entity alignment, AF2MEA). 在不失一般性的前提下, 本文从多模态知识图谱中的结构模态和视觉模态两方面出发: 一方面为解决缺陷 1), 提出三元组筛选机制, 通过无监督方法, 结合关系PageRank得分以及实体度, 为三元组打分, 并过滤掉无效三元组, 缓和结构差异性; 另一方面, 针对缺陷 2), 利用图像−文本匹配模型, 计算实体−图片的相似度得分, 设置相似度阈值以过滤噪声图片, 并基于相似度赋予图片不同权重, 生成更高质量的实体视觉特征表示. 此外, 为捕获结构信息动态变化的置信度并充分利用不同模态信息的互补性以应对缺陷 3), 本文设计自适应特征融合机制, 基于实体节点的度数以及实体与种子实体之间的距离, 动态融合实体的结构信息和视觉信息. 这种机制能够有效应对长尾实体数量占比大且结构信息相对匮乏的现实问题. 本文在多模态实体对齐数据集上进行了充分的实验及分析, 表明AF2MEA取得了最优的实体对齐效果并证实了提出的各个模块的有效性. 本文的主要贡献可总结为以下3个方面:
1)设计创新的三元组筛选模块, 基于关系PageRank评分和实体度生成三元组得分, 过滤三元组, 缓和不同知识图谱的结构差异性;
2)针对视觉信息利用差的问题, 本工作基于预训练图像−文本匹配模型, 计算实体−图片的相似度得分, 过滤噪声图片, 并基于相似度得分获得更准确的实体视觉特征表示;
3)设计自适应特征融合模块, 以可变注意力融合实体的结构特征和视觉特征, 充分利用不同模态信息之间的互补性, 进一步提升对齐效果.
本文第1节简要介绍相关工作; 第2节介绍问题定义和整体框架; 第3节具体介绍本文提出的多模态实体对齐模型; 第4节明确实验设置, 进行实验并分析结果; 第5节为结束语.
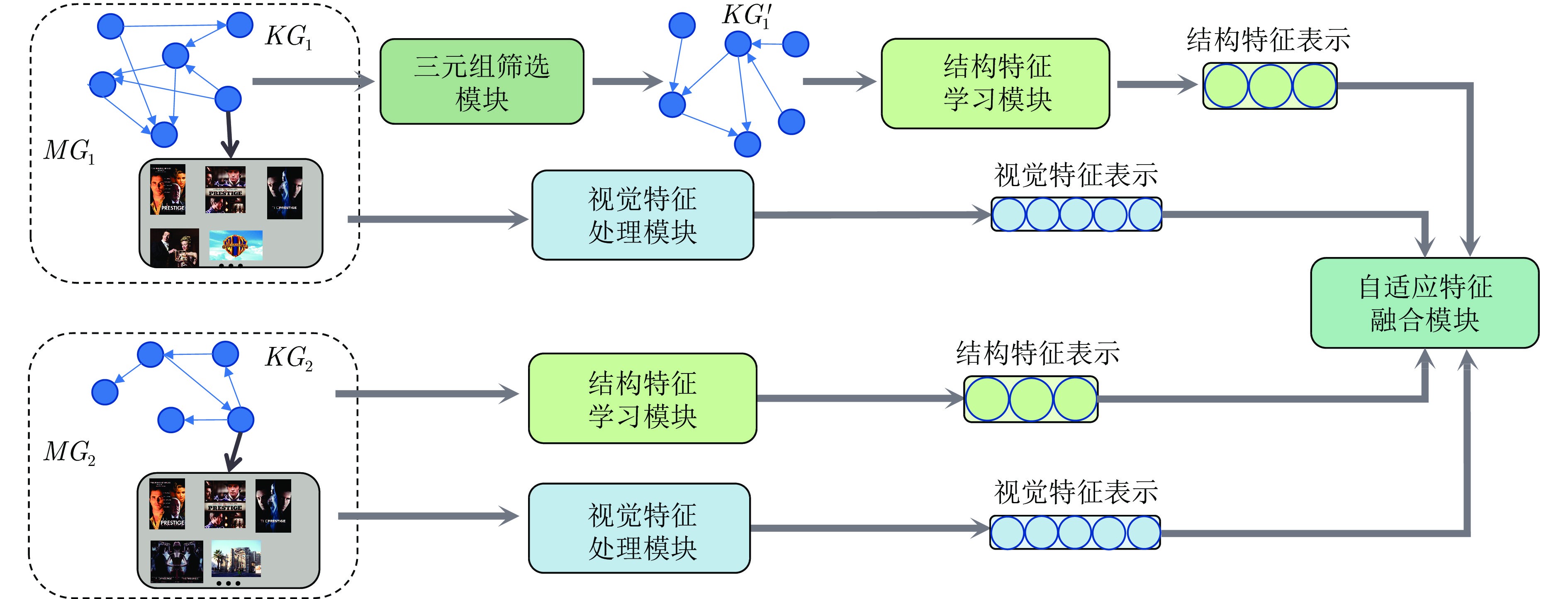
图 2 自适应特征融合的多模态实体对齐框架
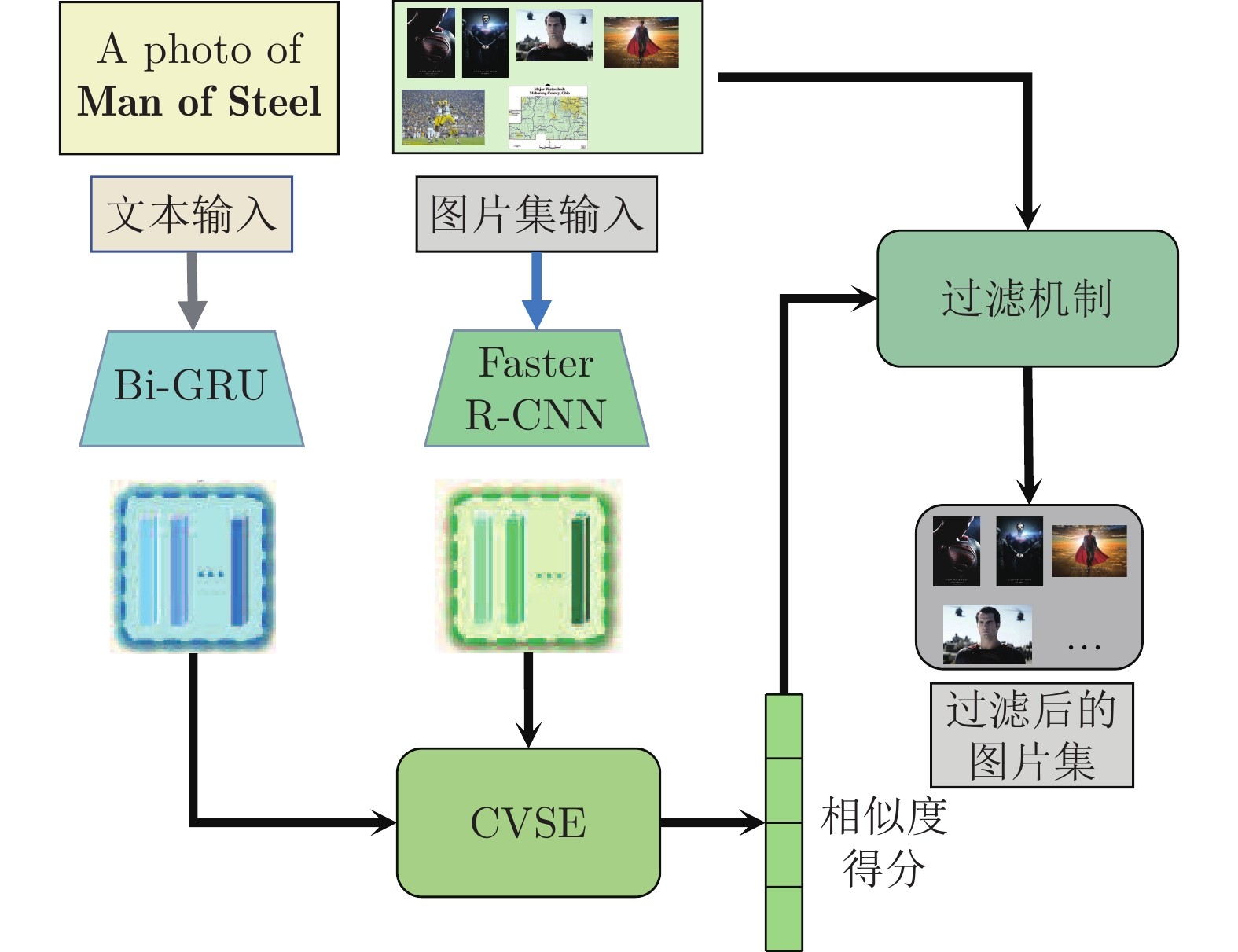
图 3 视觉特征处理模块
为解决多模态知识图谱不完整的问题, 本文提出自适应特征融合的多模态实体对齐方法AF2MEA, 设计自适应特征融合机制实现多种模态信息有效融合, 充分利用多模态信息间的互补性. 并且, 当前多模态知识图谱中视觉信息利用率不高, 本文基于预训练的图像−文本匹配模型, 设计了视觉特征处理模块, 为实体生成更精确的视觉特征表示. 此外, 注意到不同知识图谱之间存在较大的结构差异限制实体对齐的效果, 本文设计三元组筛选机制, 缓和结构差异. 该模型在多模态实体对齐数据集上取得最好的效果, 并显著提升实体对齐准确率.
后续工作将进一步研究多模态特征联合表示、预训练实体对齐模型等多模态实体对齐的相关问题, 构建高效可行的多模态知识图谱融合系统.
作者简介
郭浩
国防科技大学博士研究生. 主要研究方向为知识图谱构建与融合技术. E-mail: guo_hao@nudt.edu.cn
李欣奕
博士, 国防科技大学讲师. 主要研究方向为自然语言处理和信息检索. 本文通信作者. E-mail: lixinyimichael@163.com
唐九阳
国防科技大学教授. 主要研究方向为智能分析, 大数据和社会计算. E-mail: 13787319678@163.com
郭延明
国防科技大学副教授. 主要研究方向为深度学习, 跨媒体信息处理与智能博弈对抗. E-mail: guoyanming@nudt.edu.cn
赵翔
国防科技大学教授. 主要研究方向为图数据管理与挖掘和智能分析. E-mail: xiangzhao@nudt.edu.cn
https://blog.sciencenet.cn/blog-3291369-1434497.html
上一篇:基于慢特征分析的分布式动态工业过程运行状态评价
下一篇:基于多示例学习图卷积网络的隐写者检测