博文
保持隐私性和原始性的物联网数据收集研究(2017-现在)
|
随着信息技术的迅猛发展,数据的收集、存储与运用已成为现代社会的核心要素。物联网技术,作为实体设备与互联网之间的纽带,正逐步融入我们日常生活的各个层面。得益于RedCap、NB-IoT、5G等新兴物联网技术的不断涌现,企业通过收集和分析数据能够更好地了解市场需求,优化产品和服务,提升竞争力;
政府可以通过收集和分析公共数据,提高社会治理的精细化水平,更好地服务于民众;除此之外,大量数据的收集为人工智能、大数据分析等技术的发展提供了丰富的“燃料”,推动了科技创新的进步。
然而,物联网应用的普及也带来了诸多隐私安全挑战。随着各类传感器和智能设备的广泛应用,大量个人行为数据和生活习惯信息被收集,如果没有妥善保护,可能导致个人隐私泄露;数据的商业价值使得一些企业可能在未经用户同意的情况下收集、使用甚至交易用户数据,引发数据滥用问题;另外,物联网设备的普及增加了网络攻击的潜在入口,黑客可能通过窃取或篡改数据来实施网络攻击,影响社会稳定和公共安全。这些风险引发了国家和社会对数据隐私保护的高度关注,2024年3月19日,国务院办公厅发布了《扎实推进高水平对外开放更大力度吸引和利用外资行动方案》,该方案明确提出了完善数据跨境流动规则、科学界定重要数据范畴等措施,旨在进一步强化《网络安全法》、《数据安全法》和《个人信息保护法》的法律规制。通过进行安全有效的数据收集工作,能够有效地规避风险,发挥数据效用。
目前,数据收集领域已经提出了许多有效的隐私保护方案,包括差分隐私、k-匿名以及联邦学习等。然而,传统的众多数据收集方案收集到的数据为一定范围内的平均值、最大值或者带有噪声的数据。尽管某些情况下这些数据也能发挥一定的价值,但若能收集用户的原始数据,提高数据的可用性,在一些场景下则更为实用。例如,在使用传感器隐私收集患者的心率、血氧等数据时,只有原始数据能够反映患者的真实身体状况,让医生给出更为精确的诊断。因此,N-源匿名技术应运而生。
N-源匿名技术将用户的数据扩展为其原始尺寸的N倍长度,原始数据被安置于扩展后数据中的特定位置,而其余位置则由零值填充。通过确保每个用户的数据存放位置各不相同且保持私密,隐私聚合技术能够准确地收集所有用户的原始数据。由于用户数据的具体存放位置保持不公开,这有效地防止了通过聚合数据追溯至个别数据所有者的可能性,保障了用户的隐私。在N-源匿名的过程中,如何高效地进行位置分配成为了关键问题。
目前,位置分配方案主要分为以下三类:1、通过可信第三方为用户分配位置。这种方法虽然效率较高,但由于其高度中心化的特性,导致鲁棒性不足,且难以找到一个普遍被所有用户信任的第三方机构;2、通过洗牌算法shuffle为用户分配位置。在此过程中,每个用户生成一个随机数,并按照预定的数据传输顺序,使用所有下游用户的公钥对其进行加密,随后进行密文的传输和洗牌。用户在完成洗牌操作后,依次使用自己的私钥解密密文。当序列中的最后一名用户完成解密,将形成一个乱序的用户随机数序列,此时每位用户都能确定自己的位置。然而,在数据收集任务的参与者众多时,这种方案会导致通信和计算成本大幅增加,且位于序列末尾的参与者需等待较长时间;3、通过随机选择方案为用户分配位置。首先生成一个长度大于或等于用户数的向量,每位用户选择一个位置并填入自己选择的随机数。聚合过程中,若未发生冲突,则完成该用户的位置分配;若出现冲突,则用户需重新随机选择并重复聚合操作,直至每位用户都获得位置。然而,在随机选择方案中,冲突检测需要通过聚合操作来实现,这不仅意味着大量的通信和计算成本,而且所需的聚合次数也无法预先确定。
除此之外,现有的方案尚无法有效支持对用户进行快速重复的位置分配。考虑到用户可能会随时加入或退出系统,并且需要被分配至不同的组别以完成各种数据收集任务,实现一个能够迅速响应多次位置分配的机制显得尤为重要。如果每次变动都需要重新执行所有步骤,将导致极高的资源消耗和时间延迟。因此,当面临用户迁移或新任务生成等情况时,应当采取一种快速且低开销的位置更新策略,以提升系统的整体性能。
针对以上问题,从2017年开始我们在N-源匿名方面开展了长期的研究,发表的论文包括[1-4]。文献[1]中,我们首先提出了基于shuffle的N-源匿名原始数据收集方案;文献[2]中,我们对存储进行了优化,提升方案效率;文献[3]中,我们提出了一种优于shuffle的原始数据收集方案,进一步降低开销;文献[4]中,我们对快速重排进一步优化,针对[3]中数据收集出现故障的用户可能无法向其他实体发送消息的问题,使用门限秘密分享方案进行优化并提升性能,并基于 Elgamal 密码系统的激励机制,对参与用户进行奖励,从而大大提高了用户参与的积极性。下面是文献[4]中所提出方案的简要工作原理:
![B(YF$][U8`JZ}APZEA}UBCK.png](http://bbs.sciencenet.cn/home.php?mod=attachment&filename=B%28YF%24%5D%5BU8%60JZ%7DAPZEA%7DUBCK.png&id=1219834)

为对比提出方案与现有方案的性能差距,文中在位置分配阶段和数据收集阶段分别与现有方案进行了理论上的对比,并进行了实验比较,结果如图1、图2所示。
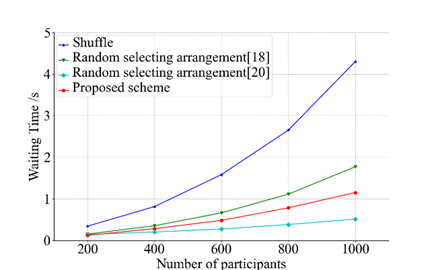
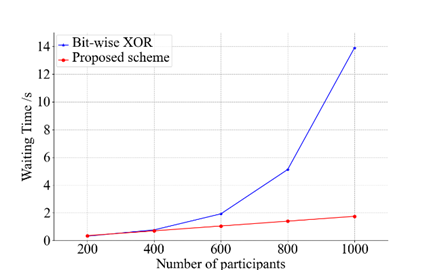
图1 位置分配阶段耗时对比 图2 数据收集阶段耗时对比
实验结果表明,Shuffle在任务中的参与人数呈指数增长。这是由于 Shuffle 的列表流工作模式造成的。此外,随机选择方案的等待时间在不同向量空间大小时有很大差异,这取决于作者对时间和空间的权衡。随着任务参与者数量的增加,按位异或方案中的 XOR 操作次数呈指数增长,远远超过了所提方案的增长率。综上所述,实验结果总体上优于现有方案。
论文信息:
[1]. Yining Liu, Yanping Wang, Xiaofen Wang, Zhe Xia, Jingfang Xu. Privacy-preserving raw data collection without a trusted authority for IoT. Computer Networks. Vol. 148, pp. 340-348, 2019.
[2]. Jingxue Chen, Gao Liu, Yining Liu. Lightweight Privacy-preserving Raw Data Publishing Scheme. IEEE Transactions on Emerging Topics in Computing. vol. 9, no. 4, pp. 2170-2174, 2021.
[3]. Jingcheng Song, Zhaoyang Han, Weizheng Wang, Jingxue Chen, Yining Liu. A new secure arrangement for privacy-preserving data collection, Computer Standards & Interfaces, Volume 80, 2022, 103582, https://doi.org/10.1016/j.csi.2021.103582.
[4]. Yixuan Huang, Yining Liu, Jingcheng Song, Weizhi Meng. A Lightweight and Efficient Raw Data Collection Scheme for IoT Systems, accepted by Journal of Information and Intelligence.
https://blog.sciencenet.cn/blog-3464286-1427793.html
上一篇:十六年所带硕士博士去向