博文
[转载]Python 爬取内容存入Excel实例
|||
# coding=UTF-8
'''
function:爬取豆瓣top250的电影信息,并写入Excel文件
'''
import requests
import re
from openpyxl import workbook # 写入Excel表所用
from openpyxl import load_workbook # 读取Excel表所用
from bs4 import BeautifulSoup as bs
import os
os.chdir('C:\Users\Administrator\Desktop') # 更改工作目录为桌面
def getHtml(src):
html = requests.get(src).content
getData(html, src) # 首页链接和其他页不同,所以单独获取信息
urls = re.findall('href="(.*filter=?)', html) # re获取获取跳转链接的href
for u in range(len(urls) - 2): # 匹配到的跳转链接最后两个重复,需去掉
next_url = 'https://movie.douban.com/top250' + urls[u]
html = requests.get(next_url).content
getData(html, next_url)
def getData(html, num_url): # html:网页源码 ,num_url:页面链接
global ws # 全局工作表对象
Name = [] # 存储电影名
Dr = [] # 存储导演信息
Ma = [] # 存储主演信息
Si = [] # 存储简介
R_score = [] # 存储评分
R_count = [] # 存储评论人数
R_year = [] # 存储年份
R_area = [] # 存储地区
R_about = [] # 存储剧情类型
soup = bs(html, 'lxml')
for n in soup.find_all('div', class_='hd'):
# ts = n.contents[1].text # 得到电影的所有名称
ts = n.contents[1].text.strip().split('/')[0] # 得到电影中文名
Name.append(ts)
for p in soup.find_all('p', class_=''):
infor = p.text.strip().encode('utf-8') #此处用utf-8编码,以免下面查找 ‘主演’下标报错
ya = re.findall('[0-9]+.*\/?', infor)[0] # re得到年份和地区
R_year.append(ya.split('/')[0]) # 得到年份
R_area.append(ya.split('/')[1]) # 得到地区
R_about.append(infor[infor.rindex('/') + 1:]) # rindex函数取最后一个/下标,得到剧情类型
try:
sub = infor.index('主演') # 取得主演下标
Dr.append(infor[0:sub].split(':')[1]) # 得到导演信息
mh = infor[sub:].split(':')[1] # 得到主演后面的信息
Ma.append(re.split('[1-2]+', mh)[0]) # 正则切片得到主演信息
except:
print '无主演信息'
Dr.append(infor.split(':')[1].split('/')[0])
Ma.append('无介绍...')
for r in soup.find_all('div', class_='star'):
rs = r.contents # 得到该div的子节点列表
R_score.append(rs[3].text) # 得到评分
R_count.append(rs[7].text) # 得到评论人数
for s in soup.find_all('span', 'inq'):
Si.append(s.text) # 得到简介
if len(Si) < 25:
for k in range(25 - len(Si)):
Si.append('本页有的电影没简介,建议查看核对,链接:' + num_url)
for i in range(25): # 每页25条数据,写入工作表中
ws.append([Name[i], R_year[i], R_area[i], R_about[i],
Dr[i], Ma[i], R_score[i], R_count[i], Si[i]])
if __name__ == '__main__':
# 读取存在的Excel表测试
# wb = load_workbook('test.xlsx') #加载存在的Excel表
# a_sheet = wb.get_sheet_by_name('Sheet1') #根据表名获取表对象
# for row in a_sheet.rows: #遍历输出行数据
# for cell in row: #每行的每一个单元格
# print cell.value,
# 创建Excel表并写入数据
wb = workbook.Workbook() # 创建Excel对象
ws = wb.active # 获取当前正在操作的表对象
# 往表中写入标题行,以列表形式写入!
ws.append(['电影名', '年份', '地区', '剧情类型', '导演', '主演', '评分', '评论人数', '简介'])
src = 'https://movie.douban.com/top250'
getHtml(src)
wb.save('test2.xlsx') # 存入所有信息后,保存为filename.xlsx



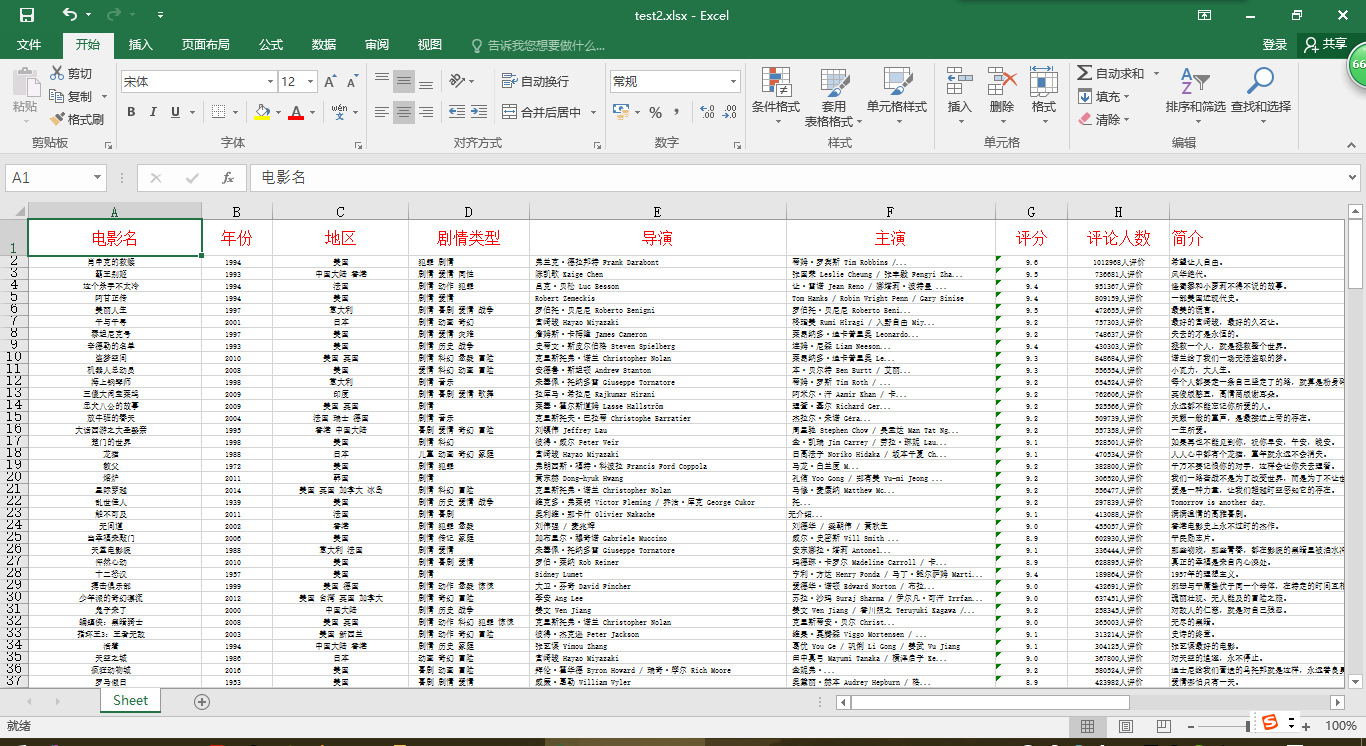
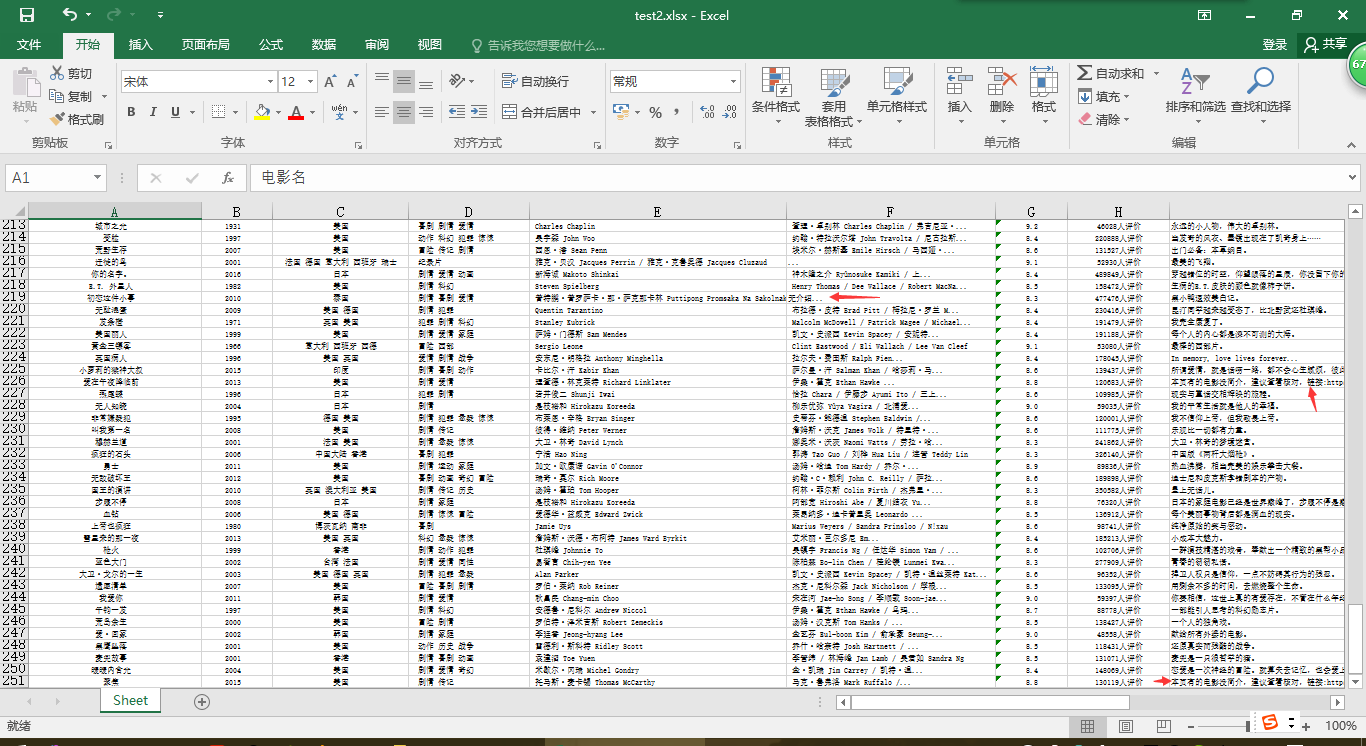
参考:https://blog.csdn.net/dick633/article/details/79933772
https://blog.sciencenet.cn/blog-3134052-1270415.html
上一篇:大学生数学建模比赛有哪些?
下一篇:ArcGIS-ENVI-eCognition的博客