І©ОД
ИЛ№¤ЙсѕНшВзјтЅй
|||
ЧоЅьФЪСРѕїDeep LearningФЪёцРФ»ЇНЖјцЦРµДУ¦УГЈ¬УЙУЪDLёъЙсѕНшВзУРєЬґуµД№ШПµЈ¬ЛчРФїЄЖЄѕНЅйЙЬПВЙсѕНшВзєНЧФјєЛщБЛЅвµЅµДЦЄК¶ЎЈЅУґҐMLК±јдІ»КЗєЬі¤Ј¬ДСГвУРГиКцІ»µ±µДµШ·ЅЈ¬ЦјФЪУЪЅ»БчС§П°Ј¬УРЙ¶Пл·ЁЦ±ЅУєуГж»ШёґЎЈ
ФЪХвЖЄІ©ОДЦРЈ¬ДгЅ«»бїґµЅИзПВЦЄК¶Јє
ЙсѕНшВзµД»щ±ѕДЈРНЈ¬З°ПтЙсѕНшВз(Feed-forward neural network)Ј¬General Feed-forward NN µДЧйјюЈ¬УЕ»ЇДї±кєЇКэЈ¬ДжПтОуІоґ«ІҐЛг·ЁЎЈ
Ў° ёщѕЭТ»ёцјт»ЇµДНіјЖЈ¬ИЛДФУЙ°ЩТЪМхЙсѕЧйіЙ ЁD ГїМхЙсѕЖЅѕщБ¬ЅбµЅЖдЛьјёЗ§МхЙсѕЎЈНЁ№эХвЦЦБ¬Ѕб·ЅКЅЈ¬ЙсѕїЙТФКХ·ўІ»Н¬КэБїµДДЬБїЎЈЙсѕµДТ»ёц·ЗіЈЦШТЄµД№¦ДЬКЗЛьГЗ¶ФДЬБїµДЅУКЬІўІ»КЗБўјґЧчіцПмУ¦Ј¬¶ш КЗЅ«ЛьГЗАЫјУЖрАґЈ¬µ±ХвёцАЫјУµДЧЬєНґпµЅДіёцБЩЅзгРЦµК±Ј¬ЛьГЗЅ«ЛьГЗЧФјєµДДЗІї·ЦДЬБї·ўЛНёшЖдЛьµДЙсѕЎЈґуДФНЁ№эµчЅЪХвР©Б¬ЅбµДКэДїєНЗї¶ИЅшРРС§П°ЎЈѕЎ№Ь ХвКЗёцЙъОпРРОЄµДјт»ЇГиКцЎЈµ«Н¬СщїЙТФід·ЦУРБ¦µШ±»їґЧчКЗЙсѕНшВзµДДЈРНЎЈ Ў±
ИЛµДґуДФКЗ·ЗіЈёґФУµДЈ¬МШ±рКЗґуДФЙсѕПµНіЈ¬їЙТФЛµГ»УРЛьЈ¬ґуДФѕНКЗТ»Р©ЧйЦЇЈ¬Пё°ы¶шТСЎЈФЪ»ъЖчС§П°БмУтЈ¬¶ФЙсѕНшВзµДСРѕїУ¦ёГКЗПЈНыґУґуДФµД№¤Чч»ъЦЖєНЙсѕПµНіЅб№№ЦР»сµГЖф·ўЈ¬Т»·ЅГжїЙТФЙијЖёЯР§µДС§П°Лг·ЁЈ¬ИГ»ъЖчТІДЬ№»¶ФОКМвЅшРРґу№жДЈС§П°Ј¬БнТ»·ЅГжїЙТФґУЙсѕФЄµДІўРР№¤Чч·ЅКЅЦеõЅЖф·ўЈ¬ЙијЖёЯР§µДІўРРјЖЛгЛг·ЁЈ¬ИГ»ъЖчУµУРёьЗїµДКµК±ґ¦Анґу№жДЈКэѕЭµДДЬБ¦ЎЈ
ФЪХвАпѕНІ»ЅйЙЬЙъОпЙПµДЙсѕНшВзБЛЈ¬Т»АґКЗІ»¶®Ј¬¶юАґХвАпµДЙсѕНшВзТ»ёЕЦё »ъЖчС§П°БмУтµДЙсѕНшВзДЈРНЈЁИЛ№¤ЙсѕНшВзЈ©Ј¬Из№ыДг¶ФХвёцЙъОпµДЙсѕНшВзёРРЛИ¤µД»°Ј¬їЙТФІОїјЎ¶A Brief Introduction to Neural Networks Ў¤ D. KrieselЎ·Ј¬ХвЖЄОДХВУРЅІµЅІ»Н¬АаРНµДЙсѕНшВзЈ¬ґу¶аКэёъЙъОпЙсѕПµНіµД»щ±ѕЅб№№УР№ШПµЎЈФЪ»ъЖчС§П°БмУтµДЙсѕНшВзТ»°г»бЦё З°Птґ«ІҐЙсѕНшВз (Feed-forward neural network)Ј¬ХвЦЦДЈРНЅПОЄНЁУГЎЈ
ИЛ№¤ЙсѕНшВзµД»щ±ѕДЈРН
З°ПтЙсѕНшВз
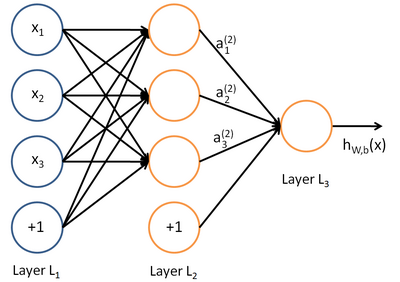
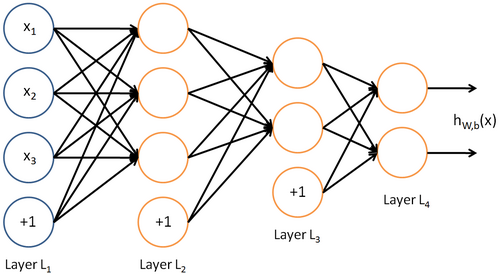
ЙПНјГиКцµДКЗТ»ёцДїЗ°СРѕїЧоОЄіЙКмShallow Ѕб№№µДЙсѕНшВзЈЁЦ»є¬УРµҐІгТюІШІгЙсѕФЄµДЅб№№Ј©ЎЈµЪТ»ІгОЄКдИлІг (input layer )Ј¬µЪ¶юІгіЖОЄТюІШІг ( hidden layer )Ј¬ЧоєуТ»ІгОЄКдіцІг( output layer )ЎЈЙсѕФЄЦ®јд¶јКЗУЙµНІгіц·ўЈ¬ЦХЦ№УЪёЯІгЙсѕФЄµДТ»МхУРПт±ЯЅшРРБ¬ЅУЈ¬ГїМх±Я¶јУРЧФјєµДИЁЦШЎЈГїёцЙсѕФЄ¶јКЗТ»ёцјЖЛ㵥ԪЈ¬ИзФЪFeed-forward neural network ЦРЈ¬іэКдИлІгЙсѕФЄНвЈ¬ГїёцЙсѕФЄОЄТ»ёцјЖЛ㵥ԪЈ¬їЙТФНЁ№эТ»ёцјЖЛгєЇКэ f() Аґ±нКѕЈ¬єЇКэµДѕЯМеРОКЅїЙТФЧФјє¶ЁТеЈ¬ПЦФЪУГµДЅП¶аµДКЗ ёРЦЄЖчјЖЛгЙсѕФЄЈ¬Из№ыДг¶ФёРЦЄЖчУРЛщБЛЅвµД»°Ј¬АнЅвЖрАґ»бИЭТЧєЬ¶аЎЈ їЙТФјЖЛгґЛК±ЙсѕФЄЛщѕЯУРµДДЬБїЦµЈ¬µ±ёГЦµі¬№эТ»¶Ё·§ЦµµДК±єтЙсѕФЄµДЧґМ¬ѕН»б·ўЙъёД±дЈ¬ЙсѕФЄЦ»УРБЅЦЦЧґМ¬Ј¬ј¤»о»тОґј¤»оЎЈФЪКµјКµДИЛ№¤ЙсѕНшВзЦРЈ¬Т»°гКЗУГТ»ЦЦёЕВКµД·ЅКЅИҐ±нКѕЙсѕФЄКЗ·сґ¦УЪј¤»оЧґМ¬Ј¬їЙТФУГ h(f) Аґ±нКѕЈ¬f ґъ±нЙсѕФЄµДДЬБїЦµЈ¬h(f) ґъ±нёГДЬБїЦµК№µГЙсѕФЄµДЧґМ¬·ўЙъёД±дµДёЕВКУР¶аґуЈ¬ДЬБїЦµФЅґуЈ¬ґ¦УЪј¤»оЧґМ¬µДёЕВКѕНФЅёЯЎЈµЅХвІї·ЦДгТСѕЅУґҐµЅБЛ№ШУЪЙсѕНшВзµДјёёц»щ±ѕКхУпЈ¬ПВГжУГёьјУ№ж·¶µД·ыєЕАґ±нКѕЈ¬ЙсѕФЄµДј¤»оЦµ(activations) f() Ј¬±нКѕјЖЛгЙсѕФЄµДДЬБїЦµ, ЙсѕФЄµДј¤»оЧґМ¬ h(f) Ј¬h ±нКѕј¤»оєЇКэЎЈ
ј¤»оєЇКэУРєГјёЦЦРОКЅЈ¬ХвАпБРѕЩБЅЦЦЈ¬
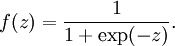
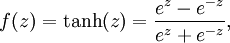
General Feed-forward NN µДЧйјю
јЩЙиУР °ьєУРNёцСщ±ѕµДКэѕЭјЇ = { (X1,T1) , (X2,T2) , (X3,T3)...... (Xn,Tn)} Ј¬ЖдЦРTµДИЎЦµїЙТФёщѕЭДгµДИООсІ»Н¬¶шІ»Н¬Ј¬±ИИзДгТЄУГЙсѕНшВзЅшРР»Ш№й·ЦОцЈ¬T ( target value)ѕНКЗТ»ёцБ¬РшЦµЈ¬Из№ыДгГж¶ФµДКЗТ»ёц»Ш№йОКМвµД»°Ј¬T µДИЎЦµѕНКЗАлЙўµДЈ¬±ИИз¶ю·ЦАаОКМв T = { 0,1 }Ј¬КдИлСщ±ѕµДГїёц№ЫІвЦµ(Observation) Xi ¶јѕЯУРПаН¬µДО¬¶ИКэБї m Ј¬УлЦ®¶ФУ¦µДКдИлІгµДЙсѕФЄёцКэТІОЄ ЈЁm + 1Ј©ёцЈ¬°ьє¬УРТ»ёцЖ«ЦГЙсѕФЄ( bais unit )ЎЈ
ХвАпІЙУГБЛAndrew NgµД Deep Learning tutorials ЙПµД·ыєЕПµНіЎЈnl±нКѕЙсѕНшВзѕЯУРµДЧЬІгКэЈ¬ 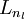 ±нКѕЧоєуТ»ІгЙсѕНшВзЈ¬ПВ±кѕНКЗ±нКѕµЪјёІгЈ¬L1±нКѕµЪТ»ІгЈ¬ТІѕНКЗКдИлІгЎЈµНІгУлёЯІгµДЙсѕФЄЦ®јд¶јКЗНЁ№эґшИЁЦШµДµҐПт±ЯЅшРРБ¬ЅУЈ¬(W,b)±нКѕХыёцЙсѕНшВзЦРµДІОКэЈ¬W ±нКѕБ¬±ЯµДИЁЦШЈ¬b±нКѕЖ«ЦГЎЈФЪЙПНјЦР(W,b) = (W(1),b(1),W(2),b(2))Ј¬ЙПЅЗ±к±нКѕµЪ i ІгУлЈЁi + 1Ј©ІгЦ®јдµДИЁЦШПµКэѕШХуЈЁИзОЮМШКвЛµГчЈ¬ПВОДЦРµДЙПЅЗ±к¶ј±нКѕІгєЕЈ¬µ±И»¶ФУЪПµКэѕШХуєНЙсѕФЄАґЛµЈ¬ЙПЅЗ±кµДТвЛјКЗІ»М«Т»СщµДЈ©Ј¬
±нКѕЧоєуТ»ІгЙсѕНшВзЈ¬ПВ±кѕНКЗ±нКѕµЪјёІгЈ¬L1±нКѕµЪТ»ІгЈ¬ТІѕНКЗКдИлІгЎЈµНІгУлёЯІгµДЙсѕФЄЦ®јд¶јКЗНЁ№эґшИЁЦШµДµҐПт±ЯЅшРРБ¬ЅУЈ¬(W,b)±нКѕХыёцЙсѕНшВзЦРµДІОКэЈ¬W ±нКѕБ¬±ЯµДИЁЦШЈ¬b±нКѕЖ«ЦГЎЈФЪЙПНјЦР(W,b) = (W(1),b(1),W(2),b(2))Ј¬ЙПЅЗ±к±нКѕµЪ i ІгУлЈЁi + 1Ј©ІгЦ®јдµДИЁЦШПµКэѕШХуЈЁИзОЮМШКвЛµГчЈ¬ПВОДЦРµДЙПЅЗ±к¶ј±нКѕІгєЕЈ¬µ±И»¶ФУЪПµКэѕШХуєНЙсѕФЄАґЛµЈ¬ЙПЅЗ±кµДТвЛјКЗІ»М«Т»СщµДЈ©Ј¬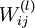 ±нКѕµЪLІгµДµЪ j ёцЙсѕФЄУлµЪ L + 1 ІгµДµЪ i ёцЙсѕФЄЦ®јдµДИЁЦШПµКэЎЈФЪЙПНјµДАэЧУЦР
±нКѕµЪLІгµДµЪ j ёцЙсѕФЄУлµЪ L + 1 ІгµДµЪ i ёцЙсѕФЄЦ®јдµДИЁЦШПµКэЎЈФЪЙПНјµДАэЧУЦР 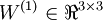 Ј¬
Ј¬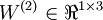 ЎЈ ёГІї·ЦІЙУГПтБї»ЇµД±нКц·ЅКЅЈ¬ХвёцОЄєуГжµДПтБї»Ї±аіМ»бґшАґ·ЗіЈґуµДєГґ¦Ј¬І»УГТ»ёцТ»ёцµДИҐјЗДДёцёъДДёцИЁЦШПµКэ¶ФУ¦Ј¬Ц±ЅУТ»ёцѕШХуЈ¬·ЗіЈјтЅаЎЈХыёцЙсѕНшВзїЙТФУГТ»ёцєЇКэ hW,b(x) Аґ±нКѕЎЈ
ЎЈ ёГІї·ЦІЙУГПтБї»ЇµД±нКц·ЅКЅЈ¬ХвёцОЄєуГжµДПтБї»Ї±аіМ»бґшАґ·ЗіЈґуµДєГґ¦Ј¬І»УГТ»ёцТ»ёцµДИҐјЗДДёцёъДДёцИЁЦШПµКэ¶ФУ¦Ј¬Ц±ЅУТ»ёцѕШХуЈ¬·ЗіЈјтЅаЎЈХыёцЙсѕНшВзїЙТФУГТ»ёцєЇКэ hW,b(x) Аґ±нКѕЎЈ
ЅУЧЕАґїґПВёъГїёцЙсѕФЄ¶јПа№ШµД·ыєЕЈ¬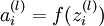 ±нКѕµЪLІгµДµЪiёцЙсѕФЄµДј¤»оЧґМ¬(activations)Ј¬ёГ№эіМКЗ·ЗПЯРФІЩЧчЈ¬ХвёцёЕДо·ЗіЈЦШТЄЈ¬ТЄАОјЗЎЈµ±L = 1µДК±єтЈ¬їЙТФИПОЄ
±нКѕµЪLІгµДµЪiёцЙсѕФЄµДј¤»оЧґМ¬(activations)Ј¬ёГ№эіМКЗ·ЗПЯРФІЩЧчЈ¬ХвёцёЕДо·ЗіЈЦШТЄЈ¬ТЄАОјЗЎЈµ±L = 1µДК±єтЈ¬їЙТФИПОЄ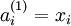 ѕНКЗµИУЪКдИлЙсѕФЄµДЦµЈ¬
ѕНКЗµИУЪКдИлЙсѕФЄµДЦµЈ¬ 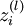 ±нКѕёГЙсѕФЄѕЯУРµДДЬБїЦµЎЈ
±нКѕёГЙсѕФЄѕЯУРµДДЬБїЦµЎЈ
µЅґЛОЄЦ№Ј¬ДгТСѕїЙТФХЖОХТ»ёцЙсѕНшВзЦРµД»щ±ѕ·ыєЕєН±нКѕ·Ѕ·ЁЈ¬ѕЎїмКмП¤ХвР©·ыєЕЈ¬ФЪДгµДДФЧУАпГжЙсѕНшВзТСѕІ»ФЩКЗійПуµДЙсѕФЄЦ®јдµДБ¬ЅУ·ЅКЅБЛЈ¬їЙТФНЁ№эЙПКцµД·ыєЕАґїМ»Ј¬Хв¶ФєуГ湫ʽµДАнЅв»бУРєЬґуµД°пЦъЎЈ
ПВГжАґїґПВЙсѕНшВзµД»щ±ѕіЙ·Ц( neural network components)
¶ФПЯРФДЈРН (Linear Model ) ±ИЅПБЛЅвµДИЛУ¦ёГ·ЗіЈКмП¤Хвёц№«КЅ

ПЯРФДЈРНїЙТФ±нКѕіЙУРПЮёц»щєЇКэ(basis function)µДПЯРФИЪєПЈ¬»щєЇКэ
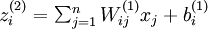 µДІЩЧчѕНїЙТФµГµЅЙсѕФЄµДДЬБїЦµЈ¬ГїёцЙсѕФЄµДј¤»оЧґМ¬ѕНїЙТФ±нКѕіЙ ( ·ЗПЯРФІЩЧч ) Ј¬ПВГж¶ФХыёцНшВзЅшРРН¬СщµДІЩЧчѕНїЙТФµГµЅ
µДІЩЧчѕНїЙТФµГµЅЙсѕФЄµДДЬБїЦµЈ¬ГїёцЙсѕФЄµДј¤»оЧґМ¬ѕНїЙТФ±нКѕіЙ ( ·ЗПЯРФІЩЧч ) Ј¬ПВГж¶ФХыёцНшВзЅшРРН¬СщµДІЩЧчѕНїЙТФµГµЅ
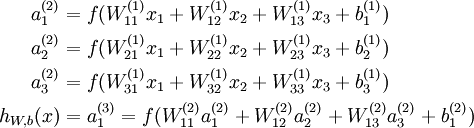
ЙПКц№эіМµДПтБї»Ї±нКѕЈ¬ХвАпµДfєНhєЇКэѕН¶ј±діЙБЛПтБїєЇКэЈ¬Из f([z1,z2,z3]) = [f(z1),f(z2),f(z3)]
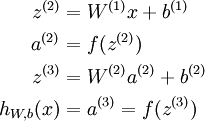
µЅёГІї·ЦЈ¬ДгТСѕ»щ±ѕХЖОХБЛТ»ёцЙсѕНшВзµДЅб№№Ј¬ИзєОЦґРеõЅКдіцЈ¬µ«КЗ»№ІоИзєОИҐСµБ·µГµЅОТГЗµДІОКэ (W,b)ЎЈЙПГж¶јКЗТФµҐТюІШІгµДЙсѕНшВз¶шЗТКдіцЦ»УРТ»ёцЙсѕФЄЈ¬Из№ыДгЦЄµАБЛИзєОИҐСµБ·ХвёцјтТЧµДЙсѕНшВзЈ¬ДЗПВГжХвёцїґЖрАґёьёґФУТ»Р©µДАэЧУДгН¬СщЦЄµАёГИзєОИҐСµБ·ЎЈ
УЕ»ЇДї±кєЇКэ
ХвёцКЗФЪУГ»ъЖчС§П°·ЅКЅОЄОКМвЅЁДЈµДµЪ¶юІїЈ¬И·¶ЁДгµДЛрК§єЇКэ(Loss Function)Ј¬ТІѕНКЗДгµДУЕ»ЇДї±кЎЈёГ№эіМ»бЙжј°µЅТ»Р©»щ±ѕµДУЕ»Ї·Ѕ·ЁЈ¬НіјЖС§ёЕДоТФј°Т»Р©КµјКµДУ¦УГѕСйЎЈµ±И»Из№ыДгёъОТТ»СщКЗёХЅУґҐ»ъЖчС§П°(Machine Learning)І»ѕГµД»°Ј¬БЛЅвБЛТ»Р©№ШУЪМЭ¶ИУЕ»Ї·Ѕ·ЁµД»°Ј¬ДгѕНДЬХЖїШХвАпµДТ»ЗРАІЎЈ
јЩЙиОТГЗУРmёцСщ±ѕ 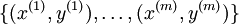 Ј¬ХвАпІЙУГµДКЗ¶юґОЖЅ·ЅєНЧоРЎ»Ї (ЧоРЎ¶юіЛ)ЧчОЄЛрК§єЇКэ(№ШУЪЛрК§єЇКэµДАаРНїЙТФІОїјЎ¶НіјЖС§П°·Ѕ·ЁЎ·- АоєЅ) Ј¬УГёГ№«КЅ±нКѕЛрК§єЇКэ
Ј¬ХвАпІЙУГµДКЗ¶юґОЖЅ·ЅєНЧоРЎ»Ї (ЧоРЎ¶юіЛ)ЧчОЄЛрК§єЇКэ(№ШУЪЛрК§єЇКэµДАаРНїЙТФІОїјЎ¶НіјЖС§П°·Ѕ·ЁЎ·- АоєЅ) Ј¬УГёГ№«КЅ±нКѕЛрК§єЇКэ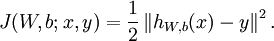 Ј¬ФЪКµјКУЕ»ЇДї±кєЇКэРиТЄ±нКѕіЙИзПВРОКЅЈ¬±ИЙПГжµД№«КЅ¶аБЛТ»ёц "+"єГєуГжµДДЪИЭЈ¬ёГПоТІіЖЧч weight decayЈ¬ёГІї·ЦКЗЖрХэФтЧчУГЈ¬·АЦ№№эДвєПЎЈ
Ј¬ФЪКµјКУЕ»ЇДї±кєЇКэРиТЄ±нКѕіЙИзПВРОКЅЈ¬±ИЙПГжµД№«КЅ¶аБЛТ»ёц "+"єГєуГжµДДЪИЭЈ¬ёГПоТІіЖЧч weight decayЈ¬ёГІї·ЦКЗЖрХэФтЧчУГЈ¬·АЦ№№эДвєПЎЈ
![.begin{align}J(W,b)&= .left[ .frac{1}{m} .sum_{i=1}^m J(W,b;x^{(i)},y^{(i)}) .right] + .frac{.lambda}{2} .sum_{l=1}^{n_l-1} .; .sum_{i=1}^{s_l} .; .sum_{j=1}^{s_{l+1}} .left( W^{(l)}_{ji} .right)^2 ..&= .left[ .frac{1}{m} .sum_{i=1}^m .left( .frac{1}{2} .left.| h_{W,b}(x^{(i)}) - y^{(i)} .right.|^2 .right) .right] + .frac{.lambda}{2} .sum_{l=1}^{n_l-1} .; .sum_{i=1}^{s_l} .; .sum_{j=1}^{s_{l+1}} .left( W^{(l)}_{ji} .right)^2.end{align}](http://deeplearning.stanford.edu/wiki/images/math/4/5/3/4539f5f00edca977011089b902670513.png)
Ц®ЛщТФІЙУГ¶юґОЛрК§єЇКэЈ¬ОТПлУ¦ёГКЗОЄБЛ№№ЅЁТ»ёцѕЯУР convex РФЦКµДДї±кєЇКэЈ¬±гУЪК№УГМЭ¶ИУЕ»ЇµД·Ѕ·ЁС°ХТЧоУЕЦµЎЈПВНјѕНКЗФЪІОКэ(w,b)ПВµДОуІоЗъГж(error surface)ЎЈ

ПВГ湫ʽ±нКѕБЛИЁЦШПµКэёьРВµД·ЅКЅЈ¬ТІѕНКЗОЄБЛХТµЅТ»ёцК№µГДї±кєЇКэЧоРЎЦµµДПµКэ (w,b) ЎЈФЪХыёцУЕ»ЇµД№эіМЦРЈ¬ЧоЦШТЄµДѕНКЗИзєОЗуЅвІ»Н¬µДМЭ¶ИРЕПўЈ¬ОЄБЛЗуЅвХвёц¶«ОчЈ¬УЦТЄАґТ»ёцРВµДёЕДоБЛЈ¬ДжОуІоґ«ІҐ(error backpropagation)С§П°Лг·ЁЎЈ»ъЖчС§П°µДОКМвЧЬКЗ»бХвСщЈ¬ХТµЅУЕ»ЇДї±кТФєуЈ¬ѕНРиТЄПаУ¦µДС§П°Лг·ЁС°ХТЧоУЕЦµЈ¬ґЛК±µДПµКэѕНКЗОТГЗЛщТЄСЎФсµДДЈРНµДІОКэБЛЎЈ
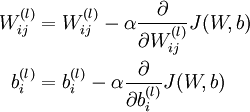
![.begin{align}.frac{.partial}{.partial W_{ij}^{(l)}} J(W,b) &=.left[ .frac{1}{m} .sum_{i=1}^m .frac{.partial}{.partial W_{ij}^{(l)}} J(W,b; x^{(i)}, y^{(i)}) .right] + .lambda W_{ij}^{(l)} ...frac{.partial}{.partial b_{i}^{(l)}} J(W,b) &=.frac{1}{m}.sum_{i=1}^m .frac{.partial}{.partial b_{i}^{(l)}} J(W,b; x^{(i)}, y^{(i)}).end{align}](http://deeplearning.stanford.edu/wiki/images/math/9/3/3/93367cceb154c392aa7f3e0f5684a495.png)
ДжПтОуІоґ«ІҐЛг·Ё (error backpropagation)
ИзЖдГыЈ¬ёГ·Ѕ·ЁѕНКЗИГКдіцІгµДy Ул КдИл x µДОуІоНщ»Шґ«ІҐЎЈТтОЄОТГЗФЪЗуГїёцІОКэµДМЭ¶ИµДК±єтКЗНЁ№э¶ФХжЦµУлФ¤ІвЦµЦ®јдµДОуІоПоЗуµјµГµЅµДЈ¬¶ФУЪКдіцЙсѕФЄ»№їЙТФЧцµЅЈ¬µ«КЗОТГЗОЮ·Ё»сИЎТюІШІгµДХжЦµЈ¬ХвѕНФміЙБЛТюІШІгµДЙсѕФЄМЭ¶ИІ»їЙЗуµДЮПЮОѕЦГжЎЈ»№єГБмУтґуЕЈГЗПлµЅБЛХвЦЦ·ЅКЅЈ¬ИГКдіцІгµДОуІоНщ»Шґ«ІҐЈ¬јЖЛгіцµЧІгЙсѕФЄµДј¤»оЧґМ¬ТЄОЄёГОуІоё¶іц¶аґуµДФрИОЈ¬ТІїЙТФАнЅвіЙёГЙсѕФЄµДОуІоЦµЈ¬УГ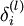 ±нКѕЈ¬
±нКѕЈ¬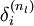 ±нКѕКдіцІгЙсѕФЄµДОуІоЎЈ
±нКѕКдіцІгЙсѕФЄµДОуІоЎЈ
ДжОуІоґ«ІҐЛг·ЁЦґРР№эіМЈє
1Ј¬ПИЦґРРТ»ґОЗ°Птґ«ІҐЈ¬јЖЛгіцГїТ»ІгµДЙсѕФЄµДј¤»оЦµЈ¬Ц±µЅКдіцІгОЄЦ№
2Ј¬¶ФУЪГїТ»ёцКдіцІгЙсѕФЄЈ¬ІЙУГИзПВ·ЅКЅјЖЛгОуІо(КµјКЙПФЪAndrewµДЧКБПЦРКЎВФБЛєЬ¶аНЖµЅІї·ЦЈ¬ёГІї·ЦОТєуГж»б·ЕЙПЈ¬ДгГЗПИАнЅвёцґуёЕ№эіМ)
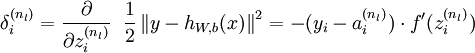
3Ј¬¶ФУЪЅПµНІгµДЙсѕФЄµДОуІоУГИзПВ№«КЅЅшРР±нКѕЈ¬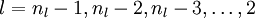
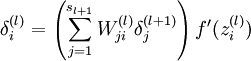
4Ј¬№ШУЪІ»Н¬ІОКэµДМЭ¶И
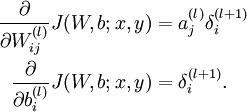
ПВГжАґїґПВПоµДѕЯМеНЖµј№эіМЎЈ
PS:ЖдКµТЄПлёьєГµДАнЅвёГНЖµј№эіМїЙТФІОїјЎ¶Pattern Recognition and Machine LearningЎ·ЦР5.3ЅЪІї·Ц№ШУЪ№АјЖОуІоєЇКэМЭ¶ИµДДЪИЭЈ¬УЙУЪАпГжІЙУГµД·ыєЕПµНіёъAndrewµДКЗПа·ґµДЈ¬ОТѕНГ»УР·ЕЙПАґЈ¬ЅиУГБЛТ»ёцјтТЧµДНЖµј№эіМЎЈ


ХЄЧФЎ¶Deep Learning ЅМіМЦРОД°жЎ·--µЛЩ©АПК¦ЦчµјЈ¬ёчВ·УўРЫєГєє№ІН¬·Тл
ПВГжАґїґТ»ёцАыУГЙсѕНшВзДвєПІ»Н¬єЇКэ(Linear Regression)µДАэЧУЈ¬ДгїЙТФФЪЎ¶Pattern Recognition and Machine LearningЎ·µД5.1ЅЪЦРХТµЅЎЈ4ё±Нј·Ц±р¶ФУ¦ЛДёцІ»Н¬µДєЇКэЈ¬ємЙ«µДКµПЯ±нКѕАыУГЙсѕНшВзДвєПµДєЇКэЈ¬ФІµг±нКѕФєЇКэЙъіЙµДСщ±ѕµгЈ¬РйПЯ±нКѕІ»Н¬µДЙсѕФЄФЪ¶ФУ¦УЪІ»Н¬ x ИЎЦµµДКдіцЦµЈ¬јёМхРйПЯѕ№эПЯРФМнјУєуµГµЅµДѕНКЗДвєПєуµДЗъПЯЎЈ

ЧЬЅбЈє
1Ј¬јтТЧµДЙсѕНшВзЅб№№ІўІ»ёґФУЈ¬µ«ФЪКµјКСµБ·Т»ёцЙсѕНшВзµДК±єтКЗ»бУцјыєЬ¶аОКМвµДЈ¬±ИИз СЎФсПЯЙПМЭ¶ИПВЅµ»№КЗBatchМЭ¶ИПВЅµ Ј¬ТюІШІгЙсѕФЄёцКэµДСЎФсЈ¬ КЗСЎФс¶аІгЙсѕНшВз»№КЗµҐІгЎЈХвР©¶јРиТЄ¶а¶аКµјщІЕРРЎЈ
2Ј¬ґУАнВЫЙПАґЅІЈ¬ЙсѕНшВзКЗїЙТФДвєПИОєОєЇКэЈ¬µ«КµјКЙПІў·ЗИзґЛЎЈѕНОТёцИЛµДКµјКѕСйАґїґЈ¬¶ФУЪДіР©КэѕЭЙсѕНшВзКЗК§°ЬµДЎЈ
3Ј¬ДЈРНІ»КЗНтДЬЈ¬»№РиТЄЧцєЬ¶а№¦їОЎЈ
#МЭ¶ИРЕПўФЪСµБ· NN ЦРµДК№УГ
#Batch МЭ¶ИЙПЙэєНПЯЙПМЭ¶ИЙПЙэµД±ИЅП
АнЅвБЛёГІї·ЦµДЙсѕНшВзЦЄК¶¶ФєуГжАнЅвЙо¶ИЙсѕНшВз»бєЬґу°пЦъЈ¬°ьАЁЖдЦРµДУЕ»Ї·Ѕ·ЁЈ¬ДЬБїДЈРНЈЁEnergy-based ModelЈ©Ј¬ТФј°RBMЈЁEBMµДТ»ёцМШАэЈ©
ІОїјОДПЧЈє
Ў¶Pattern Recognition and Machine LearningЎ·
Andrew Ng's Wiki Page http://deeplearning.stanford.edu/wiki/index.php/Neural_Networks
http://www.cppblog.com/billhsu/archive/2008/08/30/60455.html
Geoff Hinton's Coursera Lectures https://d396qusza40orc.cloudfront.net/neuralnets/lecture_slides%2Flec1.pdf
https://blog.sciencenet.cn/blog-696950-697101.html
ПВТ»ЖЄЈєЖжТмЦµ·ЦЅв(SVD) --- ПЯРФ±д»»јёєОТвТе